Story AI ที่เปลี่ยนไอเดียของคุณให้กลายเป็นโลก
สร้างเรื่องราว สร้างตัวละคร และเปลี่ยนพวกมันเป็นการ์ตูน วิดีโอ หรือเกม — ด้วย AI ทั้งหมดนี้
เริ่มต้นจากไอเดียง่าย ๆ และเปลี่ยนมันให้เป็นเรื่องราว โลกใหม่ หรือบางสิ่งที่ยิ่งใหญ่กว่าเดิม ด้วย story321, story AI ไม่ใช่แค่การสร้างผลลัพธ์ — มันคือวิธีในการสร้าง ขยาย และพัฒนา
คุณไม่ได้แค่ใช้ Story AI คุณกำลังสร้างสรรค์กับ story321
คนส่วนใหญ่ไม่ได้มีปัญหากับการหาไอเดีย พวกเขามีปัญหากับการเปลี่ยนไอเดียให้กลายเป็นสิ่งที่เป็นจริง Story321 เปลี่ยนแปลงสิ่งนั้น ด้วย story AI ที่เป็นแกนหลัก story321 ช่วยคุณ:
เปลี่ยนความคิดให้เป็นเรื่องราวที่มีโครงสร้าง
แต่งและปรับแต่งเรื่องเล่าของคุณ
สร้างบางสิ่งบางอย่างที่เติบโตขึ้นเรื่อย ๆ
จากไอเดีย สู่จักรวาล ด้วย story321
นี่คือหน้าตาของการสร้างสรรค์เมื่อ Story AI ทำงานในทางที่ถูกต้อง
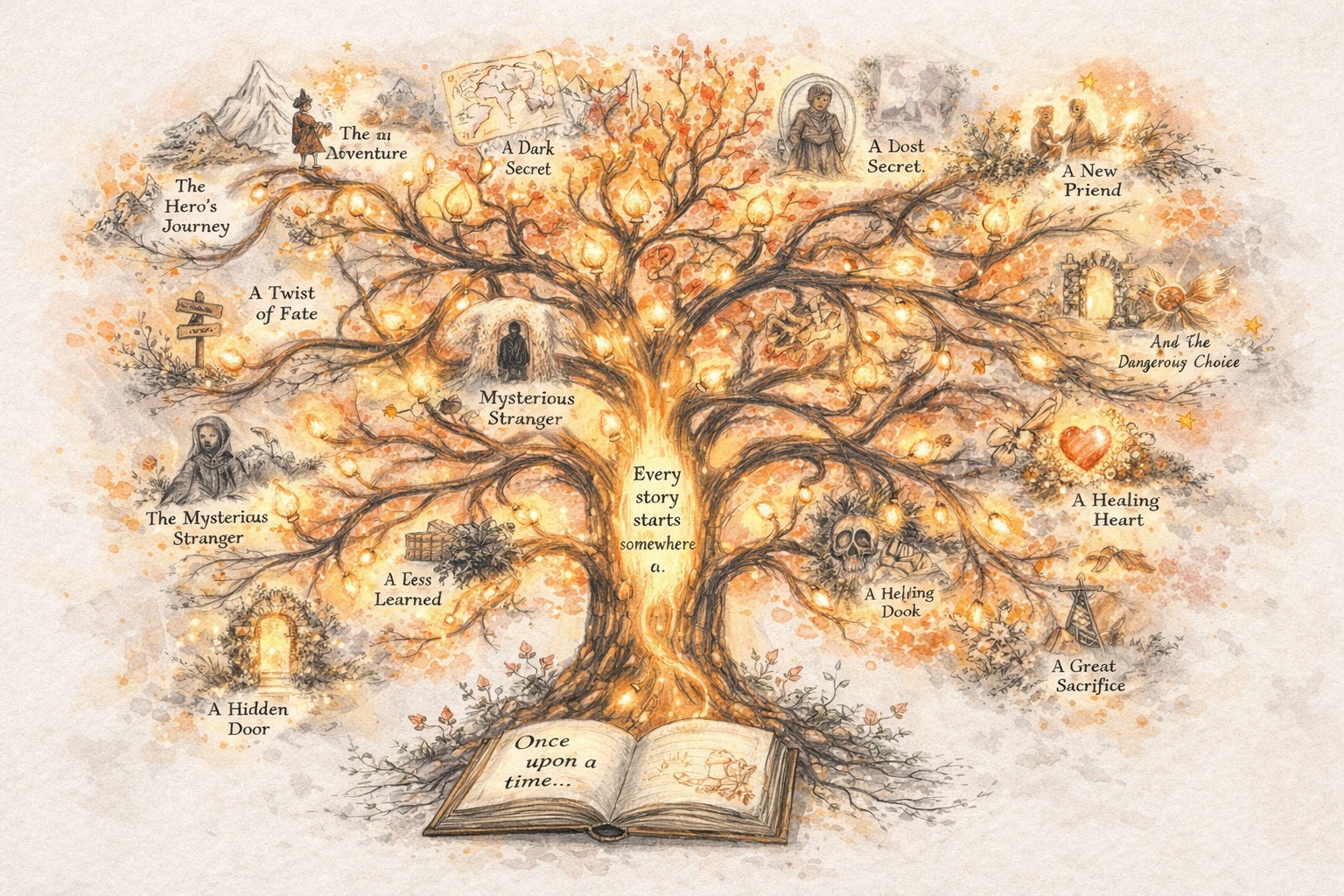
ไอเดียกลายเป็นเรื่องราว
เริ่มจากประกายไฟ แนวคิด หรือโครงเรื่องหยาบๆ story321 ช่วยเปลี่ยนมันให้เป็นเรื่องราวที่มีโครงสร้างที่คุณสามารถต่อยอดได้จริง ๆ
เรื่องราวกลายเป็นซีรีส์
เมื่อมีเวอร์ชันแรกแล้ว คุณก็สามารถสร้างต่อไปได้ ต่อเติมโครงเรื่อง เพิ่มบท และขยายเรื่องราวเดียวให้กลายเป็นซีรีส์ที่ยั่งยืน
ซีรีส์กลายเป็นโลก
เมื่อเรื่องราวเชื่อมโยงกัน ตัวละครลึกซึ้งขึ้น และสถานที่ขยายออก สิ่งที่เริ่มต้นจากเรื่องเล่ากลายเป็นโลกที่มีตรรกะ ความทรงจำ และโมเมนตัมของตัวเอง
โลกกลายเป็นภาพและการโต้ตอบ
Story321 ช่วยให้คุณเปลี่ยนโลกนั้นเป็นการ์ตูน วิดีโอ และประสบการณ์แบบโต้ตอบ เพื่อให้การสร้างสรรค์ก้าวข้ามจากข้อความไปสู่สิ่งที่ผู้คนมองเห็นและสำรวจได้
Story321 เชื่อมโยงทุกขั้นตอน คุณไม่ใช่แค่สร้างเนื้อหา คุณกำลังสร้างบางสิ่งบางอย่างที่เติบโต
วิธีสร้างสรรค์ใหม่ด้วย Story AI
Story321 เปลี่ยนวิธีการทำงานของ Story AI — จากแค่สร้างผลลัพธ์ ไปสู่การสร้างสรรค์อย่างต่อเนื่อง
สร้างเรื่องราวที่พัฒนาขึ้น
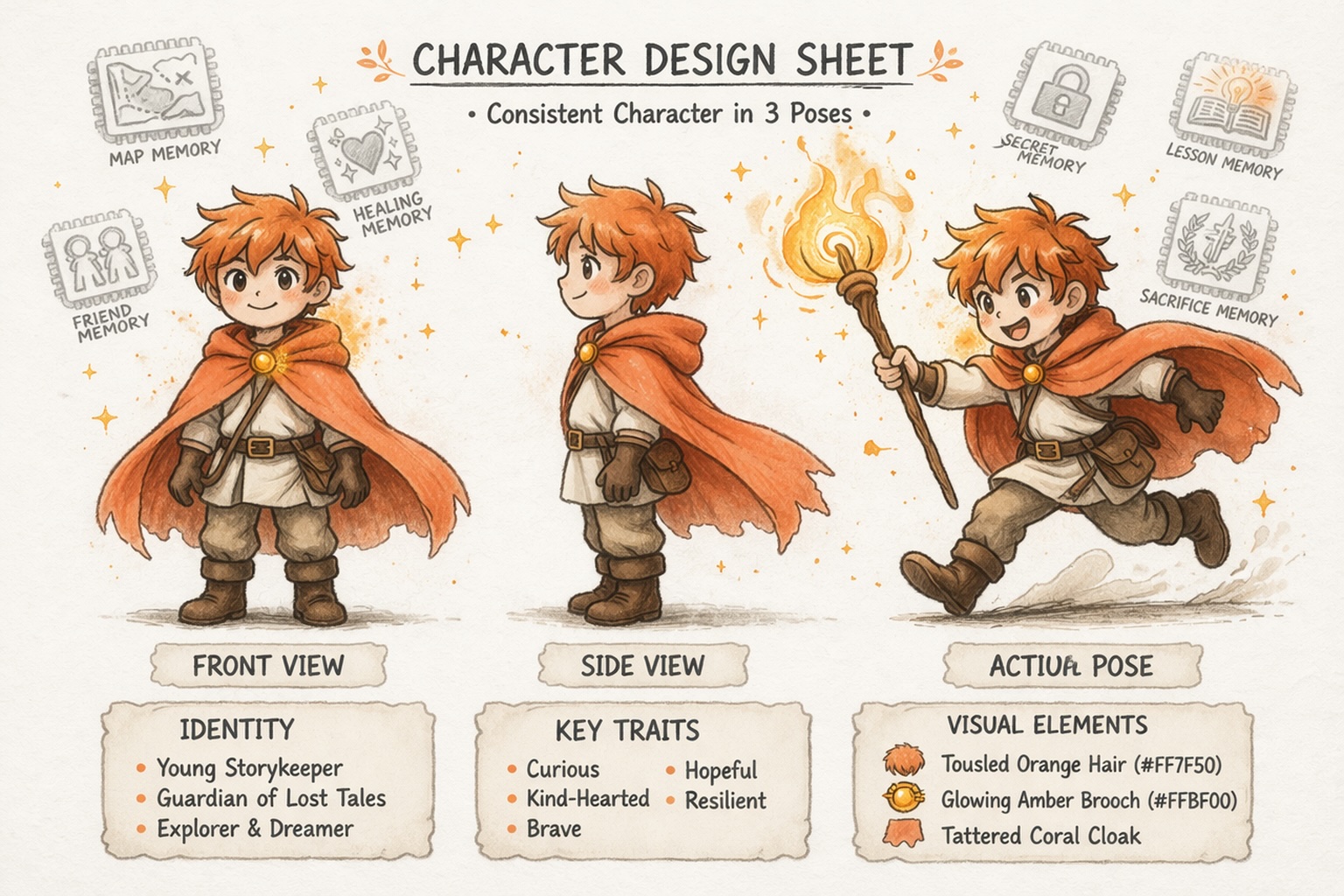
สร้างตัวละครที่คงความสอดคล้อง
พัฒนาลงไปในโลก ไม่ใช่แค่เขียนพรอมต์
ก้าวข้ามข้อความ

Story AI ไม่ควรหยุดอยู่แค่ผลลัพธ์เดียว
เครื่องมือ story AI แบบดั้งเดิมสร้างผลลัพธ์แล้วหยุดเพียงเท่านั้น Story321 สร้างมาแตกต่างกัน มันเปลี่ยน story AI ให้เป็นกระบวนการสร้างสรรค์ต่อเนื่อง โดยแต่ละขั้นตอนสร้างขึ้นจากขั้นตอนก่อนหน้า
เริ่มต้นด้วยเรื่องราว
เริ่มจากไอเดียเดียวและปั้นให้เป็นเรื่องราวที่มีทิศทาง โครงสร้าง และมีเนื้อหาพอที่จะพัฒนาได้ต่อไป
สร้างต่อโดยไม่ต้องเริ่มใหม่
แทนที่จะเริ่มต้นใหม่ทุกครั้ง ให้สร้างต่อจากสิ่งที่คุณมีอยู่แล้ว พัฒนาเรื่องราวของคุณต่อโดยยังคงรักษาบริบทและโมเมนตัมไว้
ขยายสิ่งที่มีอยู่แล้ว
นำเรื่องราวที่ใช่มาขยายออกไป เพิ่มโครงเรื่อง เงื่อน ตัวละคร และรายละเอียดของโลกโดยไม่สูญเสียแก่นแท้ที่ทำให้มันยอดเยี่ยม
แปลงเป็นรูปแบบใหม่
เปลี่ยนจากเรื่องเล่าไปเป็นการ์ตูน วิดีโอ หรือประสบการณ์แบบโต้ตอบ ด้วย story321 การสร้างสรรค์ยังคงวิวัฒนาการต่อไปแทนที่จะสิ้นสุดที่ผลลัพธ์ข้อความชิ้นเดียว
สร้างขึ้นเพื่อนักสร้างสรรค์หลากหลายประเภท
ไม่ว่าคุณจะเริ่มจากจุดไหน story321 ก็ช่วยคุณเติบโตได้
นักสร้างสรรค์หน้าใหม่
เริ่มต้นได้โดยไร้แรงกดดัน story321 ทำให้ story AI เข้าถึงได้ง่ายขึ้น เพื่อที่คุณจะได้สร้างสรรค์โดยไม่ต้องกังวลเรื่องโครงสร้างหรือประสบการณ์
นักสร้างเนื้อหา
ทำงานเร็วขึ้นและผลิตเนื้อหาแบบขับเคลื่อนด้วยเรื่องราวได้ในระดับที่มากขึ้น story321 เปลี่ยน story AI ให้กลายเป็นเครื่องมือสร้างสรรค์ที่น่าเชื่อถือ
ผู้สร้างโลก
ออกแบบตัวละคร เรื่องเล่า และระบบที่วิวัฒนาการได้ story321 ช่วยให้คุณใช้ story AI สำหรับโครงการสร้างสรรค์ระยะยาว
เหตุใด story321 จึงเปลี่ยน Story AI
Story AI จะทรงพลังมากขึ้นเมื่อมันเป็นส่วนหนึ่งของระบบ และระบบนั้นก็คือ story321
| Features | เครื่องมือ Story AI ส่วนใหญ่ | story321 |
|---|---|---|
กระแสการสร้างสรรค์ | สร้างเพียงครั้งเดียว | สร้างต่อเนื่องได้เรื่อยๆ |
ความจำของเรื่องเล่า | สูญเสียบริบท | รักษาความสอดคล้องของเรื่องเล่า |
การขยายรูปแบบ | หยุดแค่นั้น | ขยายข้ามรูปแบบต่าง ๆ |
คำถามที่พบบ่อยเกี่ยวกับ Story AI
Story AI คืออะไร และ Story321 ใช้มันอย่างไร?
Story AI คือการใช้ AI เพื่อช่วยคุณสร้างเรื่องราว ตัวละคร และโลก จากไอเดียเริ่มต้น Story321 ใช้ story AI เป็นระบบสร้างสรรค์ เพื่อให้คุณสามารถก้าวจากแนวคิดคร่าว ๆ ไปสู่เรื่องราวที่มีโครงสร้างและยังคงสร้างต่อได้ แทนที่จะต้องเริ่มใหม่ทุกครั้ง
Story AI ช่วยให้ฉันเขียนเรื่องราวเร็วขึ้นได้อย่างไร?
Story AI ช่วยให้คุณก้าวข้ามหน้าเปล่าได้ โดยเปลี่ยนไอเดียหยาบ ๆ ให้เป็นทิศทางของเรื่อง ร่างฉาก และพื้นฐานของตัวละคร ด้วย Story321 คุณสามารถปรับแต่งและขยายสิ่งที่ใช้การได้อยู่แล้ว ซึ่งทำให้กระบวนการเขียนเร็วขึ้นโดยไม่สูญเสียการควบคุมเชิงสร้างสรรค์ของคุณ
Story AI รักษาความสอดคล้องของตัวละครและโลกได้ไหม?
ได้ แต่ต้องใช้แพลตฟอร์มที่สร้างขึ้นเพื่อการสานต่อ Story321 ช่วยให้ story AI รักษาความสอดคล้องของตัวละคร โครงเรื่อง และรายละเอียดของโลก เพื่อให้คุณสามารถพัฒนาโปรเจคไปเรื่อย ๆ แทนที่จะสร้างผลลัพธ์ที่ไม่เชื่อมโยงกัน
ทำไมต้องเลือก Story321 แทนเครื่องมือ Story AI ทั่วไป?
เครื่องมือ story AI ส่วนใหญ่สร้างผลลัพธ์เดียวแล้วก็หยุด Story321 สร้างขึ้นเพื่อการสร้างสรรค์อย่างต่อเนื่อง ช่วยคุณขยายเรื่องราวเป็นการ์ตูน วิดีโอ และประสบการณ์แบบโต้ตอบ ในขณะที่ยังคงรักษาทิศทางสร้างสรรค์ ตัวละคร และตรรกะของโลกเดิมไว้
เริ่มต้นเรื่องราวแรกของคุณด้วย story321
คุณไม่จำเป็นต้องมีประสบการณ์ คุณไม่จำเป็นต้องมีไอเดียที่สมบูรณ์แบบ คุณแค่ต้องเริ่มต้น Story AI จะให้จุดเริ่มต้นแก่คุณ story321 จะช่วยคุณสร้างทุกสิ่งที่ตามมา