Story AI que Transforma Tus Ideas en Mundos
Crea historias, construye personajes y conviértelos en cómics, videos o juegos, todo con IA.
Comienza con una idea simple y conviértela en una historia, un mundo o algo aún más grande. Con story321, la IA para historias es más que una salida; se convierte en una forma de crear, expandir y construir.
No estás usando Story AI. Estás creando con story321.
La mayoría de la gente no lucha con las ideas. Lucha con convertir las ideas en algo real. Story321 cambia eso. Con la IA para historias en su núcleo, story321 te ayuda a:
Convertir pensamientos en historias estructuradas
Dar forma y refinar tu narrativa
Construir algo que crece con el tiempo
De la Idea al Universo con story321
Así es la creación cuando la IA para historias funciona de la manera correcta.
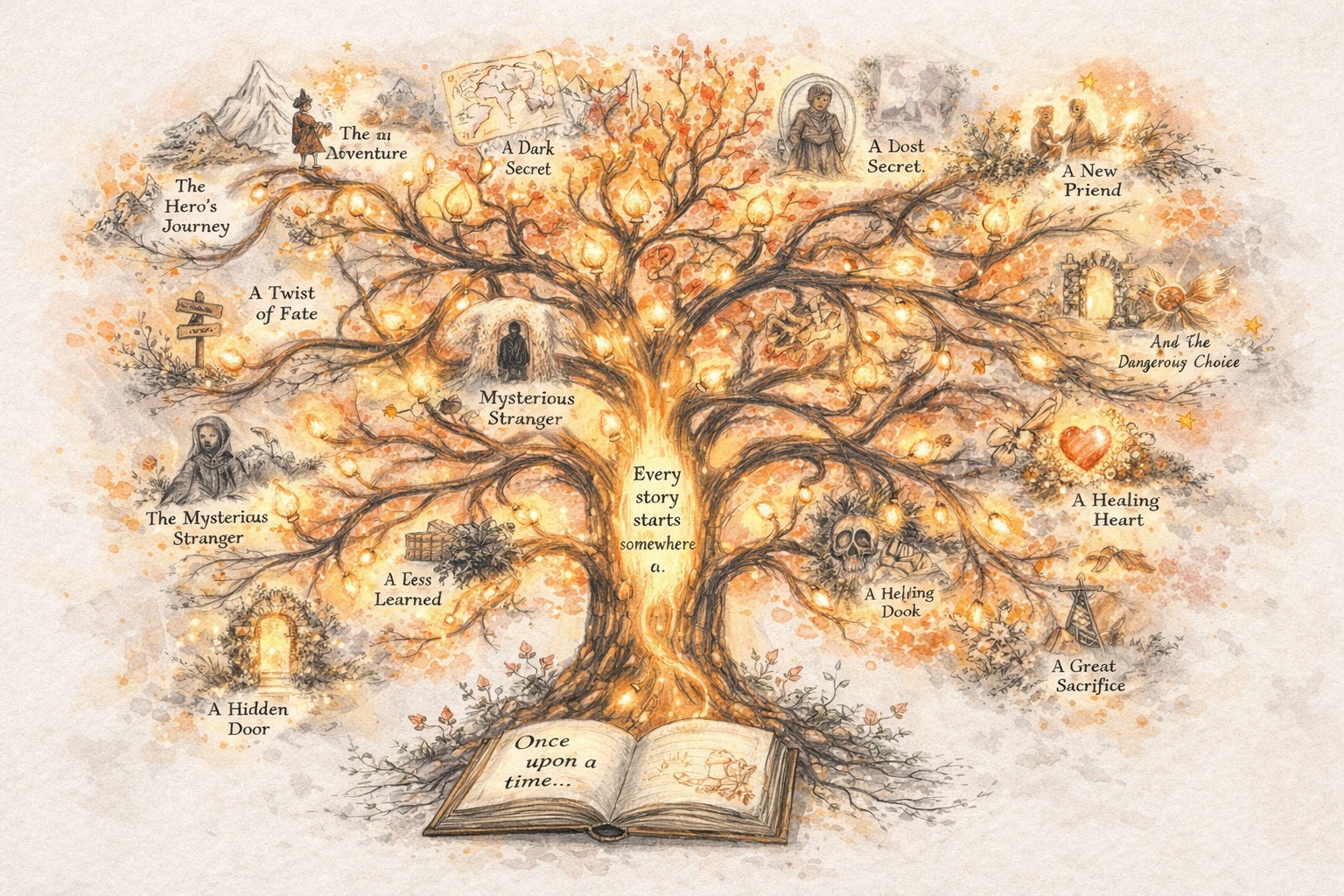
Una Idea se Convierte en una Historia
Comienza con una chispa, un concepto o una premisa aproximada. story321 te ayuda a convertirlo en una historia estructurada sobre la que realmente puedas construir.
Una Historia se Convierte en una Serie
Una vez que existe la primera versión, puedes continuar. Extiende arcos, añade capítulos y haz crecer una historia en algo serializado y sostenido.
Una Serie se Convierte en un Mundo
A medida que las historias se conectan, los personajes se profundizan y los escenarios se expanden. Lo que comenzó como una narrativa se convierte en un mundo con su propia lógica, memoria y momentum.
Un Mundo se Convierte en Visual e Interactivo
Story321 te permite transformar ese mundo en cómics, videos y experiencias interactivas, para que la creación vaya más allá del texto y se convierta en algo que la gente pueda ver y explorar.
Story321 conecta cada paso. No solo estás generando contenido. Estás construyendo algo que crece.
Una Nueva Forma de Crear con Story AI
Story321 transforma cómo funciona la IA para historias, pasando de la simple generación a la creación continua.
Crea Historias que Evolucionan
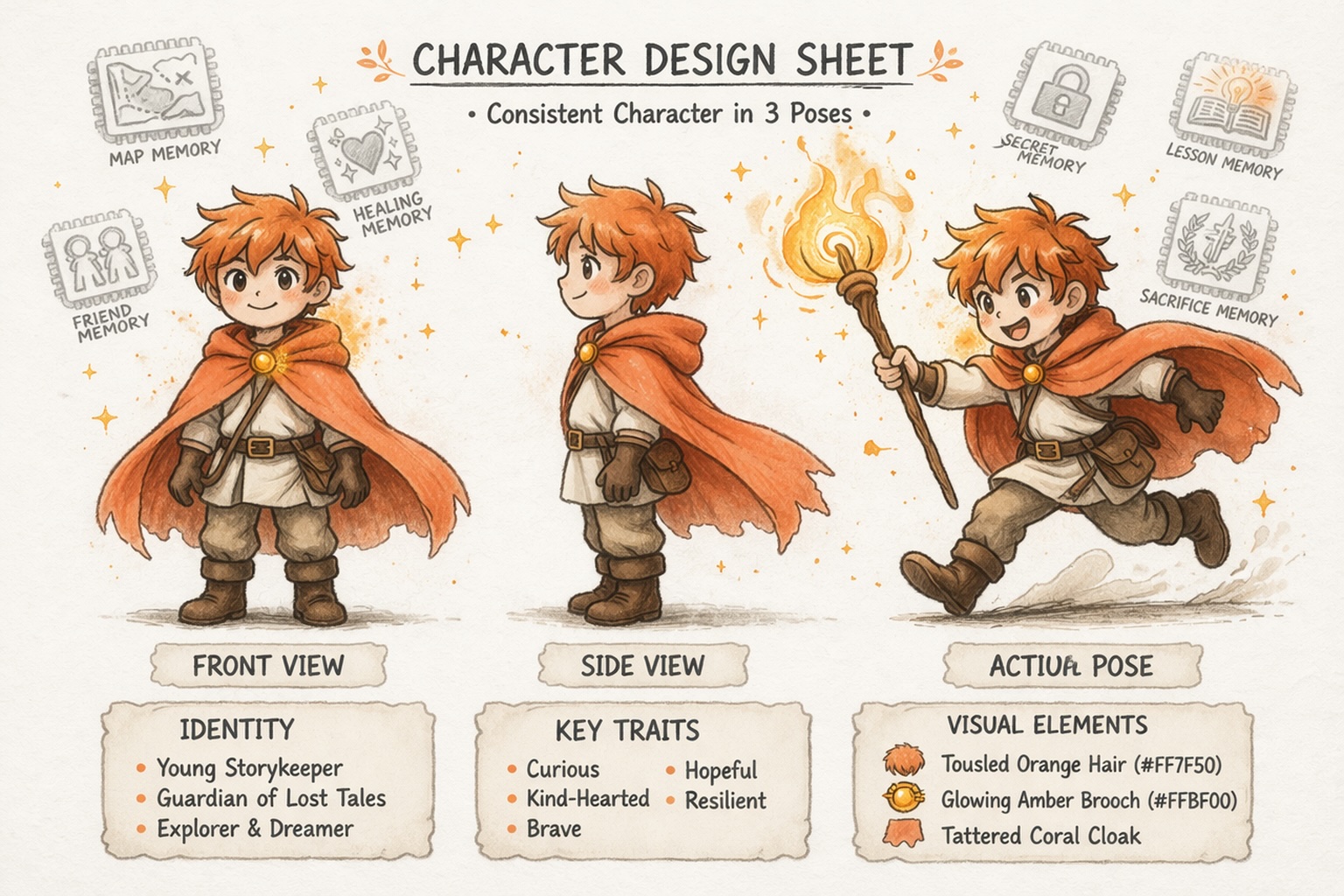
Construye Personajes que se Mantienen Coherentes
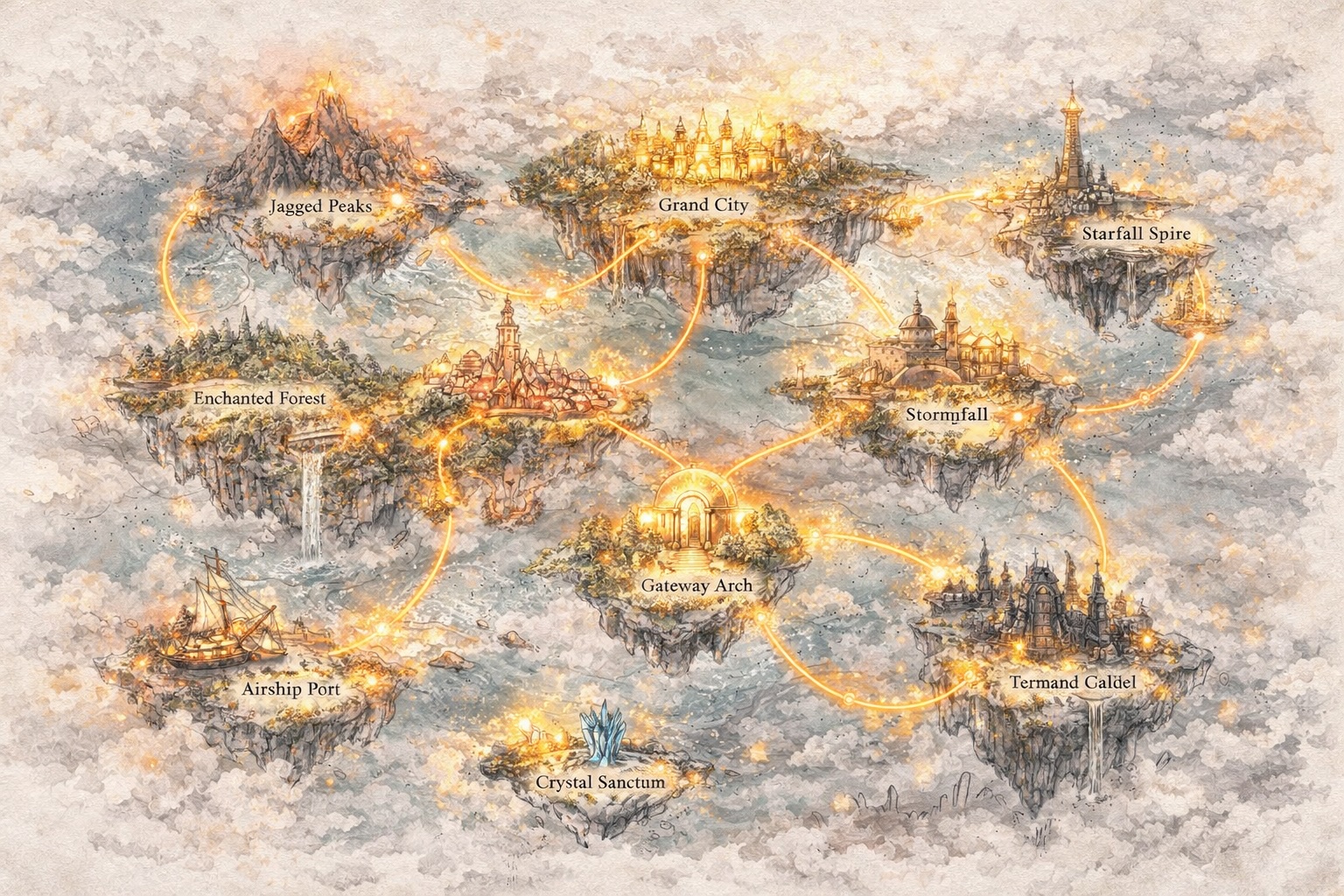
Desarrolla Mundos, No Solo Indicaciones
Ve Más Allá del Texto

La IA para Historias No Debería Detenerse Tras una Salida
Las herramientas tradicionales de IA para historias generan una vez y se detienen ahí. Story321 está construida de manera diferente. Convierte la IA para historias en un proceso creativo continuo donde cada paso se construye sobre el anterior.
Comienza con una Historia
Empieza con una sola idea y dale forma hasta convertirla en una historia con dirección, estructura y suficiente sustancia para seguir desarrollándola.
Continúa Sin Reiniciar
En lugar de empezar de cero cada vez, sigue construyendo a partir de lo que ya existe. Continúa tu historia preservando el contexto y el momentum.
Expande lo que Funciona
Toma una historia prometedora y hazla crecer. Añade arcos, capas, personajes y detalles del mundo sin perder el núcleo de lo que la hizo funcionar.
Transforma en Nuevos Formatos
Pasa de la historia al cómic, video o experiencia interactiva. Con story321, la creación sigue evolucionando en lugar de terminar en una sola salida de texto.
Creado para Diferentes Tipos de Creadores
No importa tu punto de partida, story321 te ayuda a crecer.
Nuevos Creadores
Comienza sin presión. story321 hace que la IA para historias sea accesible, para que puedas crear sin preocuparte por la estructura o la experiencia.
Creadores de Contenido
Trabaja más rápido y produce contenido basado en historias a escala. story321 convierte la IA para historias en un motor creativo confiable.
Constructores de Mundos
Diseña personajes, narrativas y sistemas que evolucionan. story321 te ayuda a usar la IA para historias en proyectos creativos a largo plazo.
Por Qué story321 Cambia la IA para Historias
La IA para historias se vuelve más poderosa cuando es parte de un sistema. Ese sistema es story321.
| Features | La mayoría de las herramientas de IA para historias | story321 |
|---|---|---|
Flujo Creativo | Genera una vez | Construye continuamente |
Memoria Narrativa | Pierde contexto | Mantiene la coherencia narrativa |
Expansión de Formatos | Se detiene ahí | Se expande a través de formatos |
Preguntas Frecuentes sobre la IA para historias
¿Qué es la IA para historias y cómo la usa Story321?
La IA para historias es el uso de la IA para ayudarte a crear historias, personajes y mundos a partir de una idea inicial. Story321 usa la IA para historias como un sistema creativo, para que puedas pasar de conceptos aproximados a historias estructuradas y seguir construyendo en lugar de empezar de nuevo cada vez.
¿Cómo me ayuda la IA para historias a escribir más rápido?
La IA para historias te ayuda a superar la página en blanco convirtiendo ideas sueltas en direcciones de la trama, borradores de escenas y bases para personajes. Con Story321, puedes seguir refinando y extendiendo lo que ya funciona, lo que acelera el proceso de escritura sin perder el control creativo.
¿Puede la IA para historias mantener coherentes a los personajes y mundos?
Sí, pero solo si la plataforma está construida para la continuidad. Story321 ayuda a que la IA para historias mantenga la coherencia entre personajes, tramas y detalles del mundo, para que puedas hacer crecer un proyecto con el tiempo en lugar de generar salidas desconectadas.
¿Por qué elegir Story321 en lugar de una herramienta genérica de IA para historias?
La mayoría de las herramientas de IA para historias generan una respuesta y se detienen ahí. Story321 está construida para la creación continua, ayudándote a expandir una historia en cómics, videos y experiencias interactivas manteniendo la misma dirección creativa, personajes y lógica del mundo.
Comienza tu Primera Historia con story321
No necesitas experiencia. No necesitas una idea perfecta. Solo necesitas empezar. La IA para historias te dará el comienzo. story321 te ayudará a construir todo lo que venga después.