了解 Fish Audio S2 如何通过超低延迟、逼真的情感和开源的灵活性彻底改变内容创作。了解为什么 Fish Audio S2 是视频创作者和配音演员的终极工具。
了解GPT-5.3 Instant如何通过更快的响应、改进的语气和更少的拒绝来彻底改变创意工作流程。视频创作者、作家和设计师必读。
Discover how Gemini 3.1 Flash-Lite empowers content creators with unmatched speed and cost-efficiency. Explore the features, benefits, and applications of this groundbreaking AI model.
了解 CoPaw 如何彻底改变你的创作工作流程。学习安装、配置和使用 CoPaw 进行写作、研究和多渠道管理,以提高你的生产力。
了解 Nano Banana 2 如何彻底改变创意工作流程。了解 Nano Banana 2 的速度、质量和高级功能,帮助视频创作者、设计师和作家提高效率。
了解自主人工智能代理 Perplexity Computer 如何彻底改变你的创意工作流程。了解 Perplexity Computer 是什么,它如何使用多代理编排,以及视频创作者、作家和设计师提高效率的实用方法。
你是否在问“什么是国漫”?这篇全面的指南探讨了国漫的定义、历史、独特风格以及国漫与日漫的区别,非常适合寻求灵感的内容创作者。
了解 Gemini 3.1 Pro 如何彻底改变内容创作。从高级推理到大型文件上传,了解为什么创作者正在转向 Gemini 3.1 Pro 以提高效率。
了解 GLM 5 如何通过长上下文推理、代理工具和端到端文档交付来增强视频创作者、设计师、作家和配音演员的创意工作流程。
了解 Gemini 3 Deep Think 如何帮助内容创作者通过高级推理解决复杂的现实世界挑战。了解它擅长什么、它的工作原理、基准、可用性和实际用例。
字节跳动发布了Seedance 2.0,它拥有完美的角色一致性和四模态输入,能够在2-5秒内生成高清视频。AI视频生成已经进入了导演级时代。
GPT-5.3-Codex 具有更快的代理工作流程、更强的视觉理解和顶级的网络安全。了解 GPT-5.3-Codex 如何提高视频、设计、写作和音频方面的创意生产力。
Claude Opus 4.6 带来了 100 万 token 上下文(测试版)、12.8 万 token 输出、Agent Teams、自适应思维和更智能的规划——内容创作者规划、制作和更快交付所需的一切。
Discover how Kling 3 on invideo helps creators produce 15‑second cinematic videos with native audio, multi‑shot consistency, and smarter directing—plus a detailed Kling 3 vs 2.6 comparison.
DeepSeek OCR 2 通过 DeepEncoder V2、视觉因果流、64-token 压缩和 20 万+ 页/天的吞吐量,为 OCR 带来类似人类的阅读体验——非常适合创作者。
了解 ACE Step v1.5 如何通过快速、可控的文本到音乐、混音和人声工具来增强创作者的能力——这些工具专为实际工作流程、本地使用和专业级声音而设计。
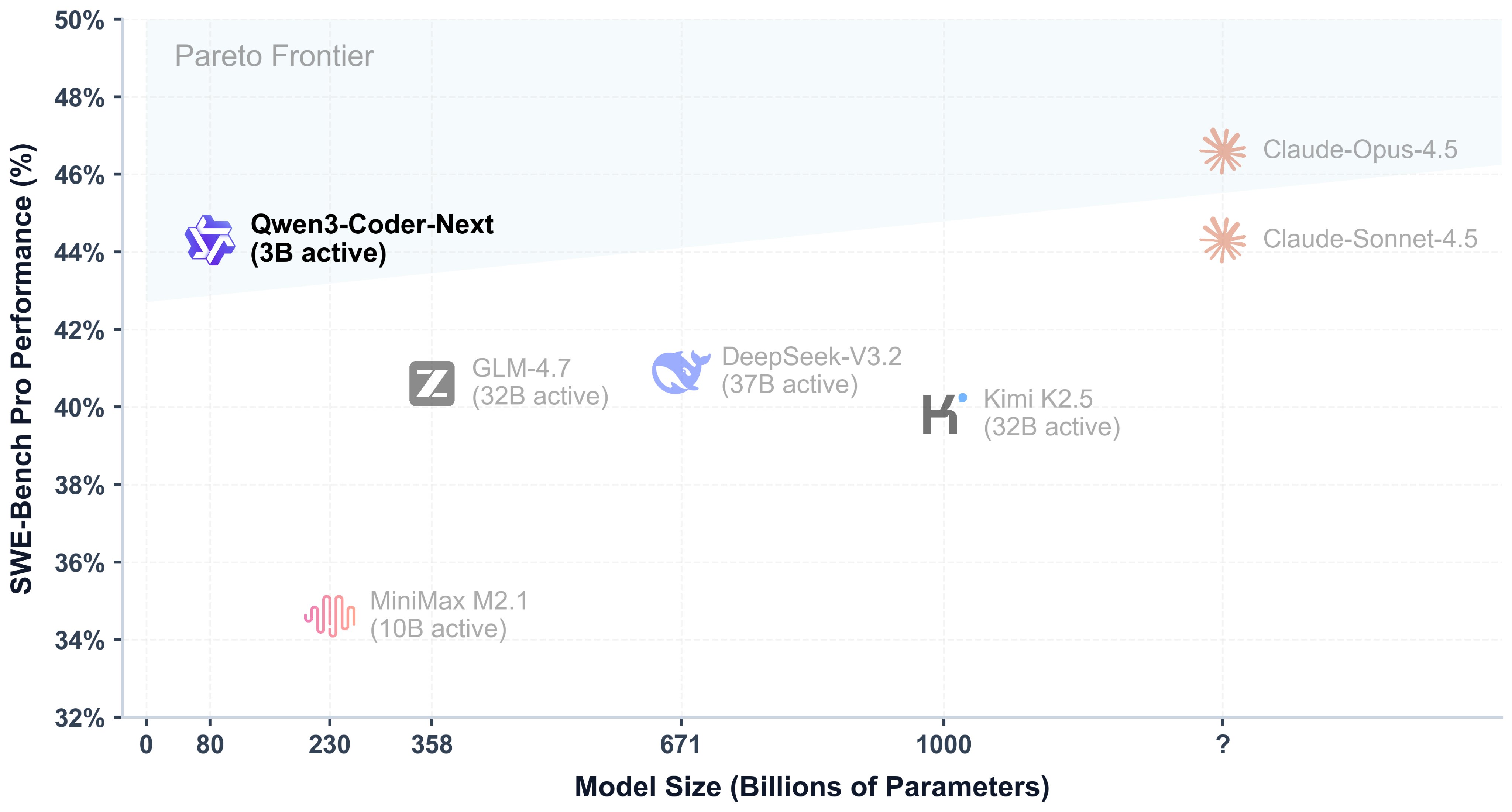
了解 Qwen3 Coder Next 如何通过 Agentic 编码、长上下文和高效的工具使用来帮助内容创作者自动化编辑、设计、写作和语音流程。
了解Codex应用是什么、它的用途以及如何使用它来自动化视频、设计、写作和音频工作流程。分步设置和提示。
探索 openclaw——一个隐私优先、开源的 AI 助手,它存在于你的聊天应用程序中,自动执行电子邮件、日历、旅行,并在本地运行,具有持久性内存。
Project Genie 将文本或图像转化为可玩的、交互式的世界。了解 Project Genie 是什么,它的工作原理(Genie、Genie 2、Genie 3),以及内容创作者如何使用它来原型设计场景、捕获素材并加速创意工作流程。
了解 Qwen3 ASR 如何帮助创作者更快地添加字幕、本地化内容,并通过准确的多语言语音识别实现编辑自动化。了解其优势以及如何使用它。
了解 Qwen3 TTS 如何通过开源、实时语音设计、3 秒克隆和多语言合成来增强创作者的能力。了解主要优势以及如何立即使用它。
探索 GLM-Image,首个开源的工业级 AR 图像模型。它采用混合 AR+扩散架构,擅长中文文本渲染、语义对齐以及针对复杂、知识密集型任务的高保真生成。
了解 Scribe v2 如何为创作者提供 150 毫秒的延迟、90 多种语言和企业级安全性。查看用例、竞争优势以及如何开始。
Niji V7 帮助内容创作者更快地制作动漫风格的故事板、关键艺术、缩略图和角色表。了解 Niji V7 的作用、比较方式以及如何个性化结果。
探索 Seedance 1.5 pro——一款适用于视频创作者、设计师、作家和配音演员的 AI 驱动的创意套件。探索功能、工作流程和提示,以提高工作效率。
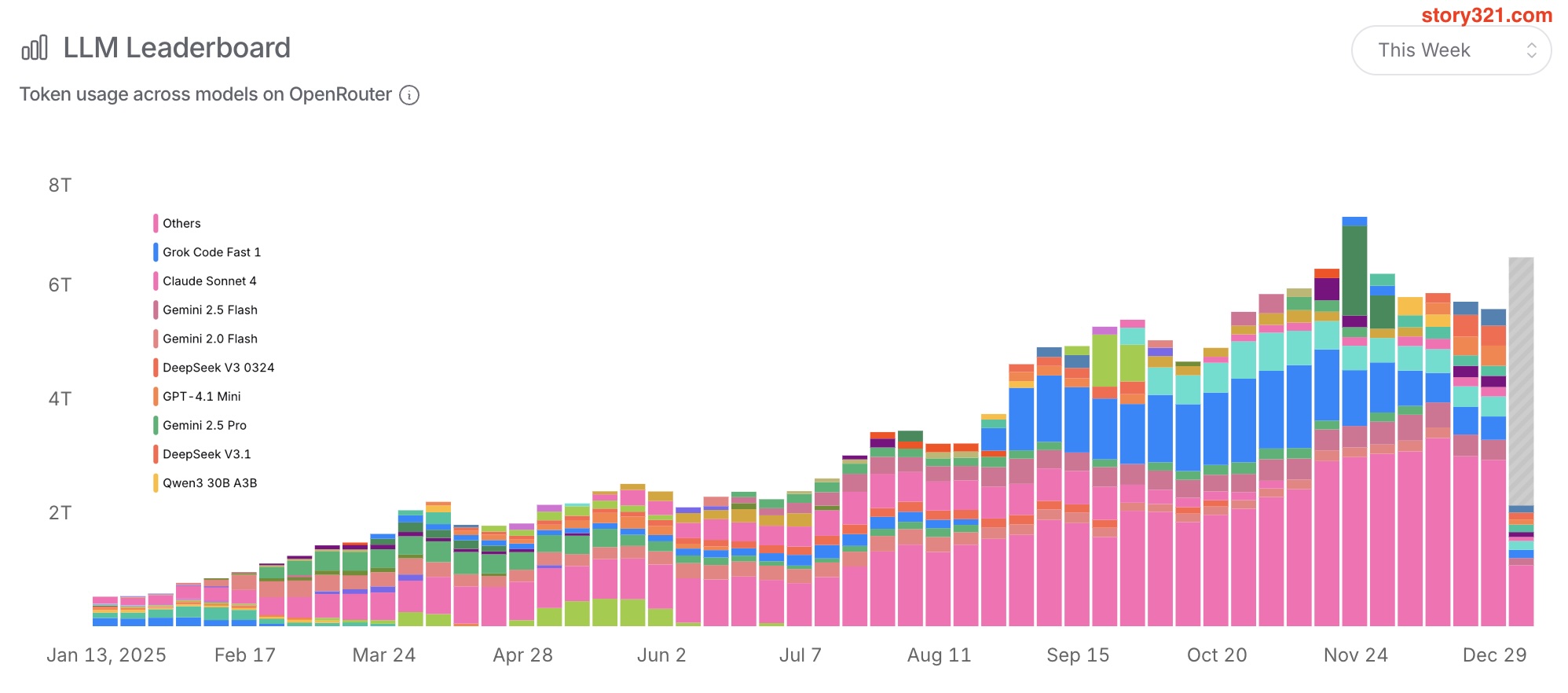
当我们步入2026年,回顾OpenRouter的2025年token使用数据,揭示了一个爆炸性增长的故事,以及AI力量平衡的根本性转变。最初由少数"前沿"巨头主导的市场,已经演变成一个以成本效益和专业
面向创作者和开发人员的 Venice AI 评测。我们测试了功能、隐私声明、图像和代码生成、定价以及 Venice AI 如何与 ChatGPT 和 Claude 相抗衡。
探索 qwen image 2512,这是一个 20B 参数的文本到图像模型,专注于人类真实感、自然纹理和准确的文本渲染。了解它最擅长什么,如何使用 diffusers,以及为什么它在开源排名中名列前茅。
了解 Ray3 Modify 如何在实现服装更换、重新照明、产品植入等功能的同时,保留真实的表演——现在在 Dream Machine 内部。