Story AI Que Transforma Suas Ideias em Mundos
Crie histórias, construa personagens e transforme-os em quadrinhos, vídeos ou jogos — tudo com IA.
Comece com uma ideia simples e transforme-a em uma história, um mundo ou algo ainda maior. Com a story321, a IA de histórias vai além de gerar conteúdo — torna-se uma forma de criar, expandir e construir.
Você Não Está Apenas Usando Story AI. Você Está Criando com a story321.
A maioria das pessoas não tem dificuldade com ideias. Elas têm dificuldade em transformar ideias em algo real. A story321 muda isso. Com a IA de histórias em seu núcleo, a story321 ajuda você a:
Transformar pensamentos em histórias estruturadas
Moldar e refinar sua narrativa
Construir algo que evolui com o tempo
Da Ideia ao Universo com a story321
É assim que a criação se parece quando a IA de histórias funciona da maneira certa.
Uma Ideia Se Torna uma História
Comece com uma faísca, um conceito ou uma premissa básica. A story321 ajuda você a transformá-la em uma história estruturada na qual você pode realmente construir.
Uma História Se Torna uma Série
Assim que a primeira versão existe, você pode continuar. Prossiga com arcos, adicione capítulos e faça uma história crescer em algo serializado e sustentado.
Uma Série Se Torna um Mundo
À medida que as histórias se conectam, os personagens se aprofundam e os cenários se expandem. O que começou como uma narrativa se torna um mundo com sua própria lógica, memória e impulso.
Um Mundo Se Torna Visual e Interativo
A story321 permite que você transforme esse mundo em quadrinhos, vídeos e experiências interativas, para que a criação vá além do texto e se torne algo que as pessoas possam ver e explorar.
A story321 conecta cada passo. Você não está apenas gerando conteúdo. Você está construindo algo que cresce.
Uma Nova Forma de Criar com Story AI
A story321 transforma como a IA de histórias funciona — passando da simples geração para a criação contínua.
Crie Histórias Que Evoluem
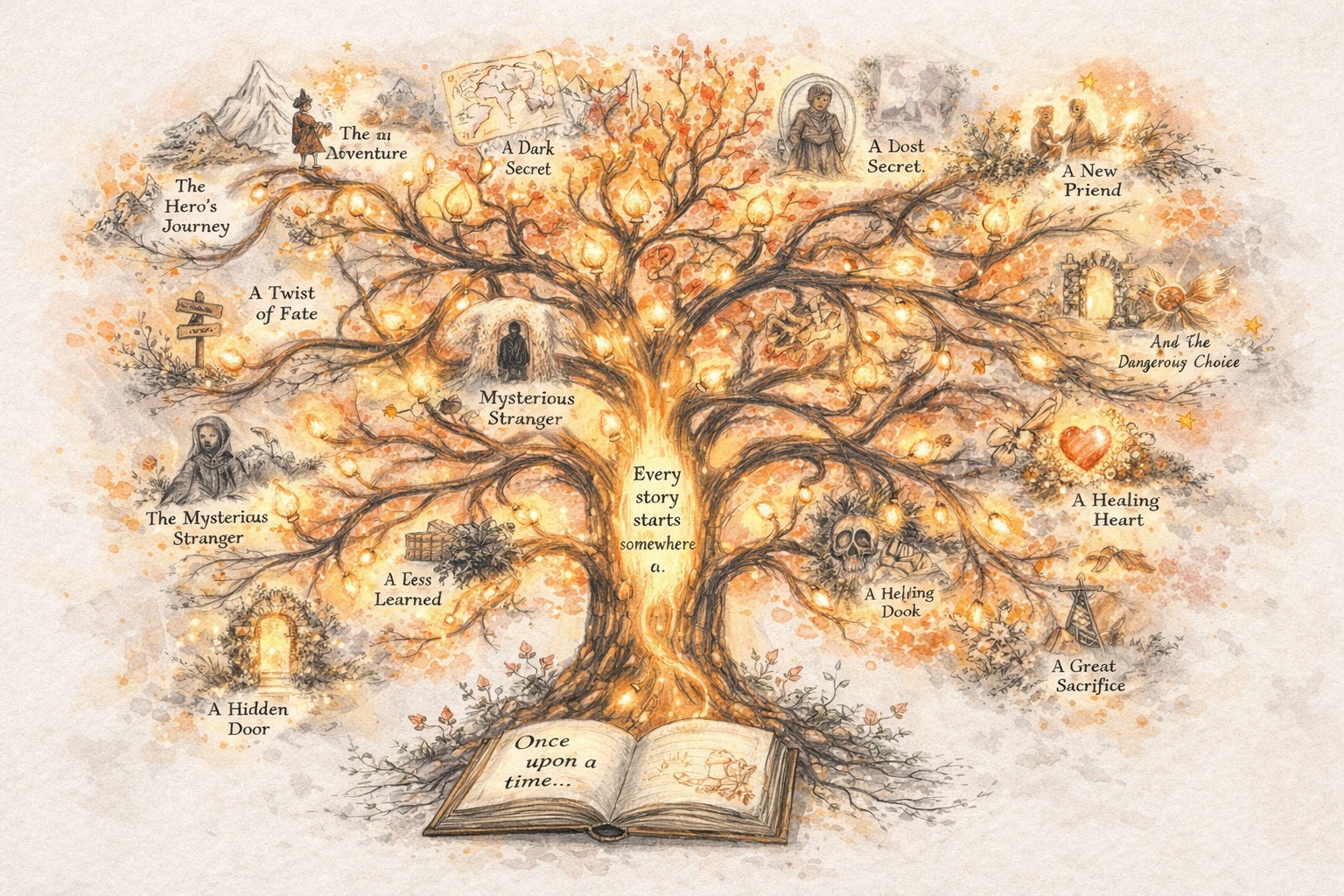
Construa Personagens Que Permanecem Consistentes
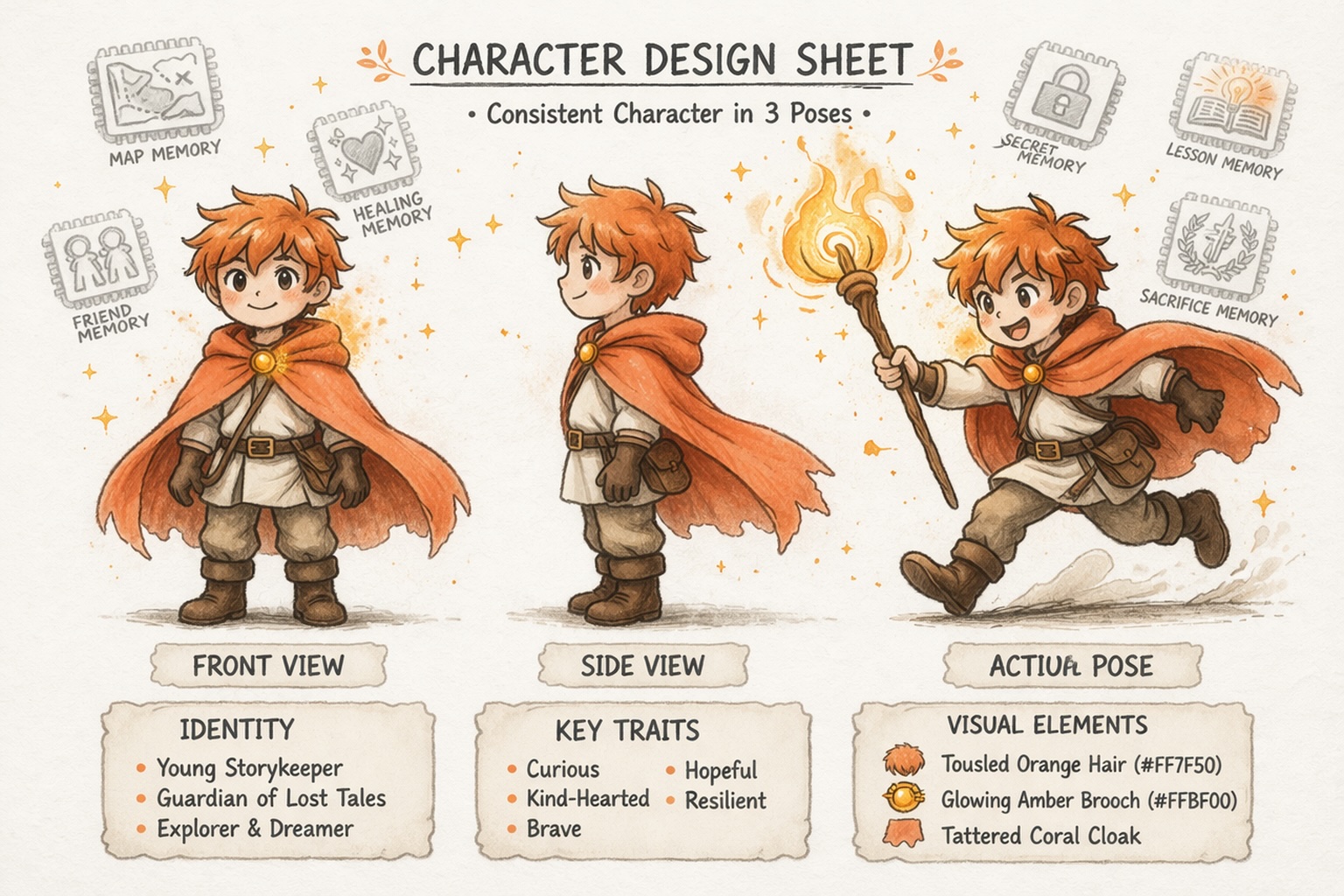
Desenvolva Mundos, Não Apenas Prompts
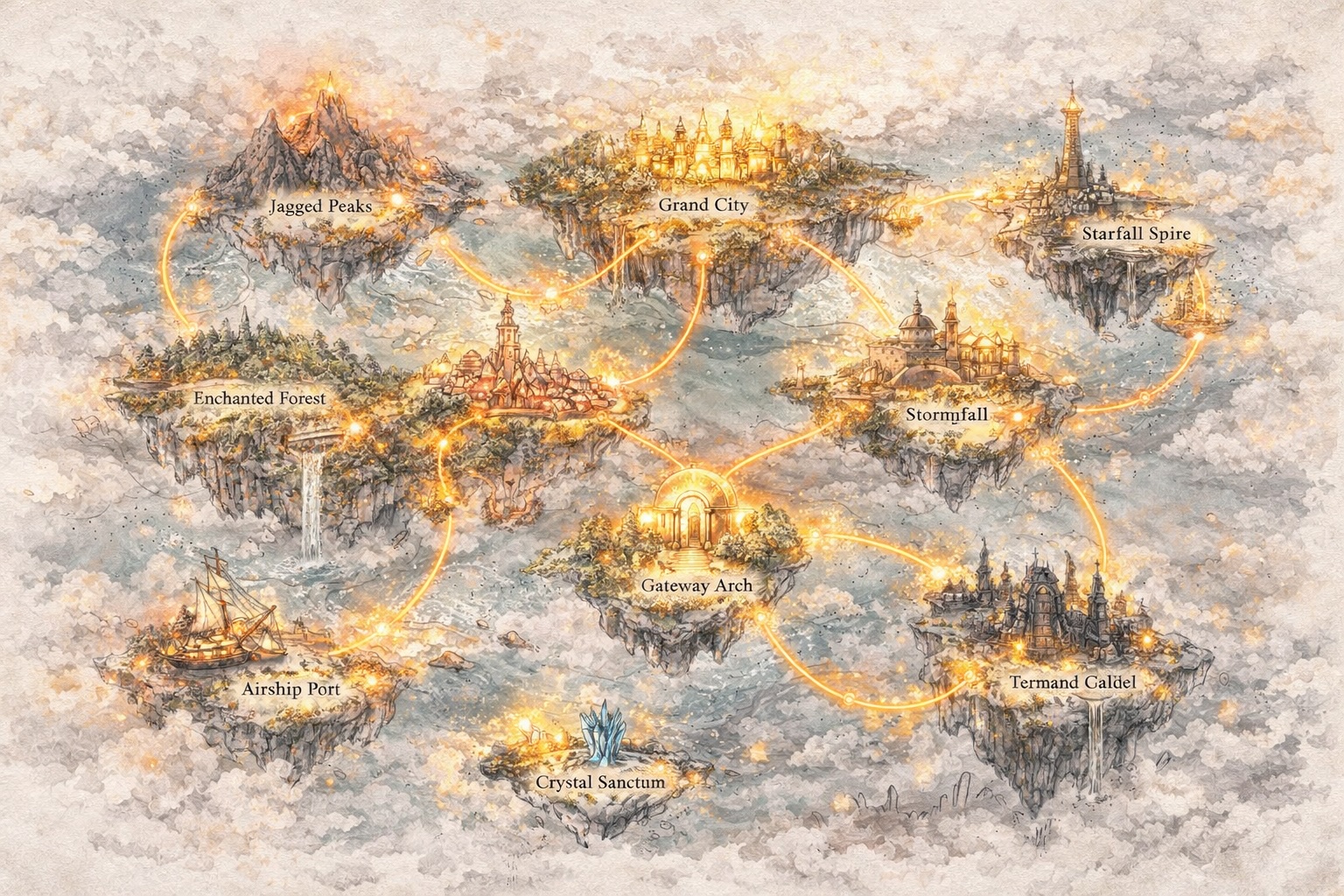
Vá Além do Texto

A Story AI Não Deve Parar Após Uma Única Saída
Ferramentas tradicionais de IA de histórias geram uma vez e param por aí. A story321 é construída de forma diferente. Ela transforma a IA de histórias em um processo criativo contínuo, onde cada passo constrói sobre o anterior.
Comece com uma História
Comece com uma única ideia e a molde em uma história com direção, estrutura e substância suficiente para continuar se desenvolvendo.
Continue Sem Reiniciar
Em vez de começar do zero toda vez, continue construindo a partir do que já existe. Continue sua história preservando o contexto e o impulso.
Expanda o Que Funciona
Pegue uma história promissora e faça-a crescer. Adicione arcos, camadas, personagens e detalhes do mundo sem perder o cerne do que a fez funcionar.
Transforme em Novos Formatos
Passe de história para quadrinho, vídeo ou experiência interativa. Com a story321, a criação continua evoluindo em vez de terminar em uma única saída de texto.
Criada para Diferentes Tipos de Criadores
Não importa o seu ponto de partida, a story321 ajuda você a crescer.
Novos Criadores
Comece sem pressão. A story321 torna a IA de histórias acessível, para que você possa criar sem se preocupar com estrutura ou experiência.
Criadores de Conteúdo
Trabalhe mais rápido e produza conteúdo orientado por histórias em escala. A story321 transforma a IA de histórias em um motor criativo confiável.
Construtores de Mundos
Projete personagens, narrativas e sistemas que evoluem. A story321 ajuda você a usar a IA de histórias para projetos criativos de longo prazo.
Por Que a story321 Muda a Story AI
A IA de histórias se torna mais poderosa quando faz parte de um sistema. Esse sistema é a story321.
| Features | A maioria das ferramentas de IA de histórias | story321 |
|---|---|---|
Fluxo Criativo | Gera uma vez | Constrói continuamente |
Memória Narrativa | Perde contexto | Mantém consistência narrativa |
Expansão de Formatos | Para por aí | Expande por vários formatos |
Perguntas Frequentes sobre IA de Histórias
O que é IA de histórias e como a Story321 a usa?
IA de histórias é o uso da IA para ajudá-lo a criar histórias, personagens e mundos a partir de uma ideia inicial. A Story321 usa a IA de histórias como um sistema criativo, para que você possa passar de conceitos iniciais para histórias estruturadas e continue construindo em vez de recomeçar a cada vez.
Como a IA de histórias me ajuda a escrever mais rápido?
A IA de histórias ajuda você a superar a página em branco, transformando ideias soltas em direções de história, rascunhos de cena e fundamentos de personagens. Com a Story321, você pode continuar refinando e estendendo o que já funciona, o que torna o processo de escrita mais rápido sem perder o seu controle criativo.
A IA de histórias pode manter personagens e mundos consistentes?
Sim, mas apenas se a plataforma for construída para continuidade. A Story321 ajuda a IA de histórias a permanecer consistente entre personagens, enredos e detalhes do mundo, para que você possa desenvolver um projeto ao longo do tempo em vez de gerar saídas desconectadas.
Por que escolher a Story321 em vez de uma ferramenta genérica de IA de histórias?
A maioria das ferramentas de IA de histórias gera uma resposta e para por aí. A Story321 é construída para criação contínua, ajudando você a expandir uma história em quadrinhos, vídeos e experiências interativas, mantendo a mesma direção criativa, personagens e lógica do mundo.
Comece Sua Primeira História com a story321
Você não precisa de experiência. Você não precisa de uma ideia perfeita. Você só precisa começar. A IA de histórias lhe dará o início. A story321 ajudará você a construir tudo o que vier depois.