Story-AI, die deine Ideen in Welten verwandelt
Erschaffe Geschichten, entwickle Charaktere und verwandle sie in Comics, Videos oder Spiele – alles mit KI.
Starte mit einer einfachen Idee und verwandle sie in eine Geschichte, eine Welt oder etwas noch Größeres. Mit story321 wird Story-AI mehr als nur Output – sie wird zu einer Methode, zu erschaffen, zu erweitern und aufzubauen.
Du nutzt nicht einfach Story-AI. Du erschaffst mit story321.
Die meisten Menschen kämpfen nicht mit Ideen. Sie kämpfen damit, Ideen in etwas Reales zu verwandeln. Story321 ändert das. Mit Story-AI im Kern hilft dir story321 dabei:
Gedanken in strukturierte Geschichten verwandeln
Deine Erzählung gestalten und verfeinern
Etwas aufzubauen, das mit der Zeit wächst
Von der Idee zum Universum mit story321
So sieht Kreation aus, wenn Story-AI richtig funktioniert.
Eine Idee wird zu einer Geschichte
Starte mit einem Funken, einem Konzept oder einer groben Prämisse. story321 hilft dir, daraus eine strukturierte Geschichte zu machen, auf der du tatsächlich aufbauen kannst.
Eine Geschichte wird zu einer Serie
Sobald die erste Version existiert, kannst du weitermachen. Führe Handlungsbögen fort, füge Kapitel hinzu und lasse eine Geschichte zu etwas Seriellem und Beständigem wachsen.
Eine Serie wird zu einer Welt
Wenn sich Geschichten verbinden, vertiefen sich Charaktere und erweitern sich Schauplätze. Was als Erzählung begann, wird zu einer Welt mit eigener Logik, Erinnerung und Dynamik.
Eine Welt wird visuell und interaktiv
Story321 ermöglicht es dir, diese Welt in Comics, Videos und interaktive Erlebnisse zu verwandeln, sodass die Kreation über Text hinausgeht zu etwas, das Menschen sehen und erkunden können.
Story321 verbindet jeden Schritt. Du generierst nicht nur Inhalte. Du baust etwas auf, das wächst.
Ein neuer Weg, mit Story-AI zu kreieren
Story321 verändert, wie Story-AI funktioniert – von einfacher Generierung zu kontinuierlichem Erschaffen.
Erschaffe Geschichten, die sich entwickeln
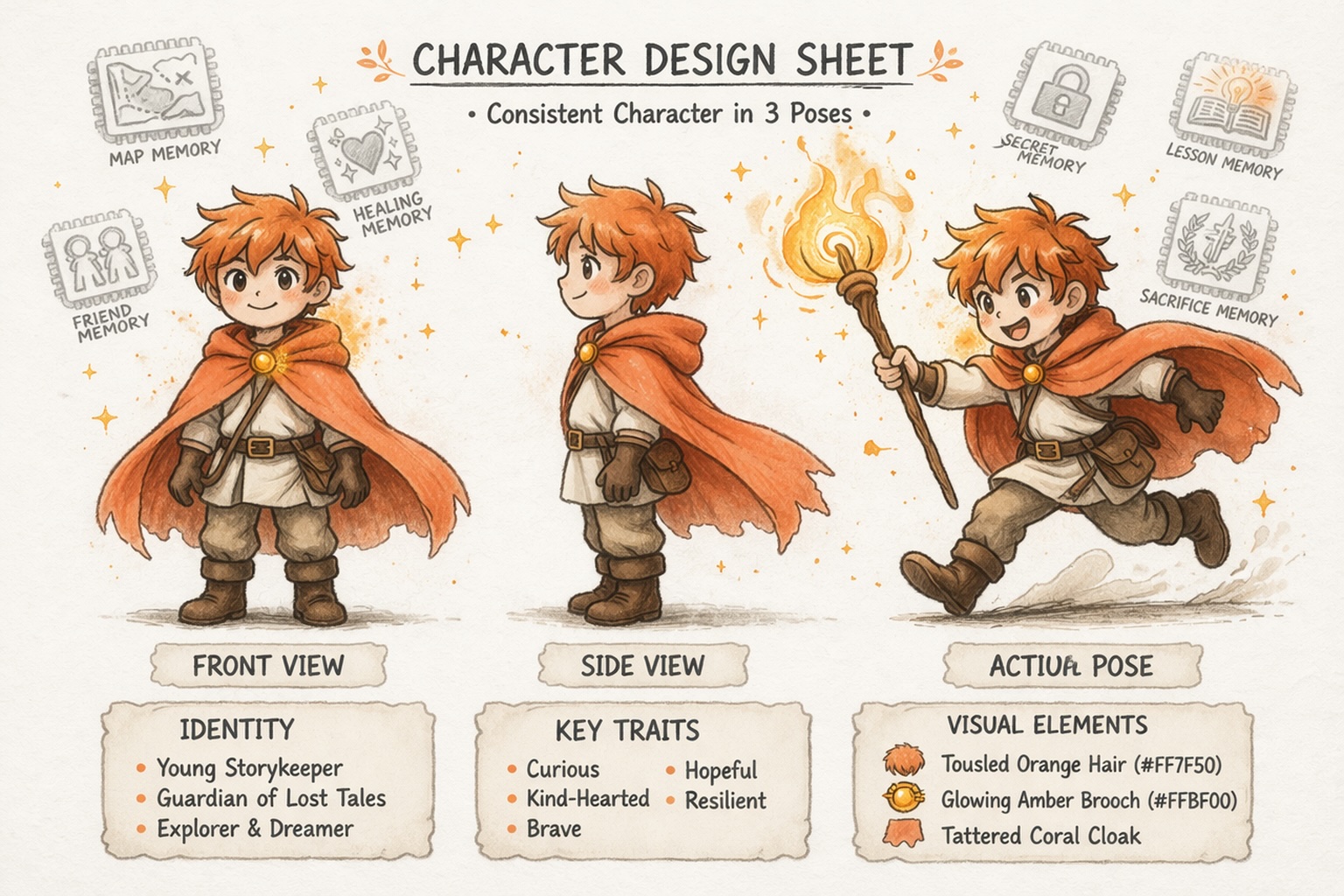
Baue Charaktere auf, die konsistent bleiben
Entwickle Welten, nicht nur Prompts
Gehe über Text hinaus

Story-AI sollte nicht nach einem Output aufhören
Traditionelle Story-AI-Tools generieren einmal und hören dann auf. Story321 ist anders aufgebaut. Es verwandelt Story-AI in einen kontinuierlichen kreativen Prozess, bei dem jeder Schritt auf dem vorherigen aufbaut.
Starte mit einer Geschichte
Beginne mit einer einzigen Idee und forme sie zu einer Geschichte mit Richtung, Struktur und genug Substanz für die weitere Entwicklung.
Fahre fort, ohne neu anzufangen
Anstatt jedes Mal von vorne zu beginnen, baue auf dem bereits Vorhandenen auf. Führe deine Geschichte fort und bewahre dabei Kontext und Schwung.
Erweitere, was funktioniert
Nimm eine vielversprechende Geschichte und lasse sie weiter wachsen. Füge Bögen, Ebenen, Charaktere und Weltendetails hinzu, ohne den Kern zu verlieren, der sie erfolgreich machte.
Verwandle in neue Formate
Wechsle von Geschichte zu Comic, Video oder interaktivem Erlebnis. Mit story321 entwickelt sich die Kreation ständig weiter, anstatt bei einem einzigen Text-Output zu enden.
Gebaut für verschiedene Arten von Kreativen
Egal, wo du startest, story321 hilft dir zu wachsen.
Neue Kreative
Starte ohne Druck. story321 macht Story-AI zugänglich, sodass du ohne Sorgen um Struktur oder Erfahrung kreieren kannst.
Content Creator
Arbeite schneller und produziere geschichtengetriebene Inhalte im großen Maßstab. story321 macht Story-AI zu einem verlässlichen kreativen Motor.
World Builder
Gestalte Charaktere, Erzählungen und Systeme, die sich entwickeln. story321 hilft dir, Story-AI für langfristige kreative Projekte einzusetzen.
Warum story321 Story-AI verändert
Story-AI wird mächtiger, wenn sie Teil eines Systems ist. Dieses System ist story321.
| Features | Die meisten Story-AI-Tools | story321 |
|---|---|---|
Kreativer Fluss | Einmal generieren | Baut kontinuierlich weiter |
Narratives Gedächtnis | Verliert Kontext | Bewahrt narrative Konsistenz |
Format-Erweiterung | Bleibt stehen | Erweitert sich über Formate |
Häufig gestellte Fragen zu Story-AI
Was ist Story-AI und wie nutzt Story321 sie?
Story-AI ist die Nutzung von KI, um dir bei der Erschaffung von Geschichten, Charakteren und Welten aus einer ersten Idee zu helfen. Story321 nutzt Story-AI als kreatives System, sodass du von groben Konzepten zu strukturierten Geschichten gelangst und weiterbauen kannst, anstatt jedes Mal neu anzufangen.
Wie hilft mir Story-AI, schneller Geschichten zu schreiben?
Story-AI hilft dir über die leere Seite hinweg, indem sie lockere Ideen in Erzählrichtungen, Szenenentwürfe und Charaktergrundlagen verwandelt. Mit Story321 kannst du bereits Funktionierendes weiter verfeinern und ausbauen, was den Schreibprozess beschleunigt, ohne deine kreative Kontrolle zu verlieren.
Kann Story-AI Charaktere und Welten konsistent halten?
Ja, aber nur wenn die Plattform für Kontinuität gebaut ist. Story321 hilft Story-AI, über Charaktere, Handlungsstränge und Weltendetails hinweg konsistent zu bleiben, sodass du ein Projekt über Zeit wachsen lassen kannst, anstatt unzusammenhängende Outputs zu generieren.
Warum Story321 statt eines generischen Story-AI-Tools wählen?
Die meisten Story-AI-Tools generieren eine Antwort und hören dann auf. Story321 ist für kontinuierliches Erschaffen gebaut, hilft dir, eine Geschichte zu Comics, Videos und interaktiven Erlebnissen zu erweitern und bewahrt dabei dieselbe kreative Richtung, Charaktere und Weltlogik.
Starte deine erste Geschichte mit story321
Du brauchst keine Erfahrung. Du brauchst keine perfekte Idee. Du musst nur anfangen. Story-AI gibt dir den Anfang. story321 hilft dir, alles danach aufzubauen.