Story AI qui Transforme vos Idées en Univers
Créez des histoires, développez des personnages et transformez-les en comics, vidéos ou jeux — tout avec l'IA.
Commencez avec une simple idée et transformez-la en histoire, en univers, ou en quelque chose encore plus grand. Avec story321, l'AI narrative devient plus qu'une simple production — elle devient un moyen de créer, développer et construire.
Vous n'Utilisez pas Story AI. Vous Créez avec story321.
La plupart des gens ne manquent pas d'idées. Ils ont du mal à transformer ces idées en réalité. Story321 change cela. Avec l'AI narrative intégrée en son cœur, story321 vous aide :
Transformer des pensées en histoires structurées
Élaborer et perfectionner votre narration
Construire quelque chose qui se développe au fil du temps
De l'Idée à l'Univers avec story321
Voici ce que la création ressemble quand l'AI narrative fonctionne correctement.
Une Idée devient une Histoire
Commencez avec une inspiration, un concept ou une premise approximative. story321 vous aide à la transformer en une histoire structurée que vous pouvez réellement développer.
Une Histoire devient une Série
Une fois la première version existante, vous pouvez continuer. Développer des arcs, ajouter des chapitres, et faire croître une histoire en quelque chose sérialisé et durable.
Une Série devient un Univers
Comme les histoires se connectent, les personnages se approfondissent et les cadres se développent. Ce qui a commencé comme une narration devient un univers avec sa propre logique, mémoire et dynamique.
Un Univers devient Visuel et Interactif
Story321 vous permet de transformer cet univers en comics, vidéos et expériences interactives, faisant ainsi évoluer la création au-delà du texte en quelque chose que les gens peuvent voir et explorer.
Story321 connecte chaque étape. Vous ne générez pas juste du contenu. Vous construisez quelque chose qui se développe.
Une Nouvelle Façon de Créer avec Story AI
Story321 transforme le fonctionnement de l'AI narrative — passant de la simple génération à la création continue.
Créez des Histoires qui Évoluent
Construisez des Personnages qui Restent Cohérents
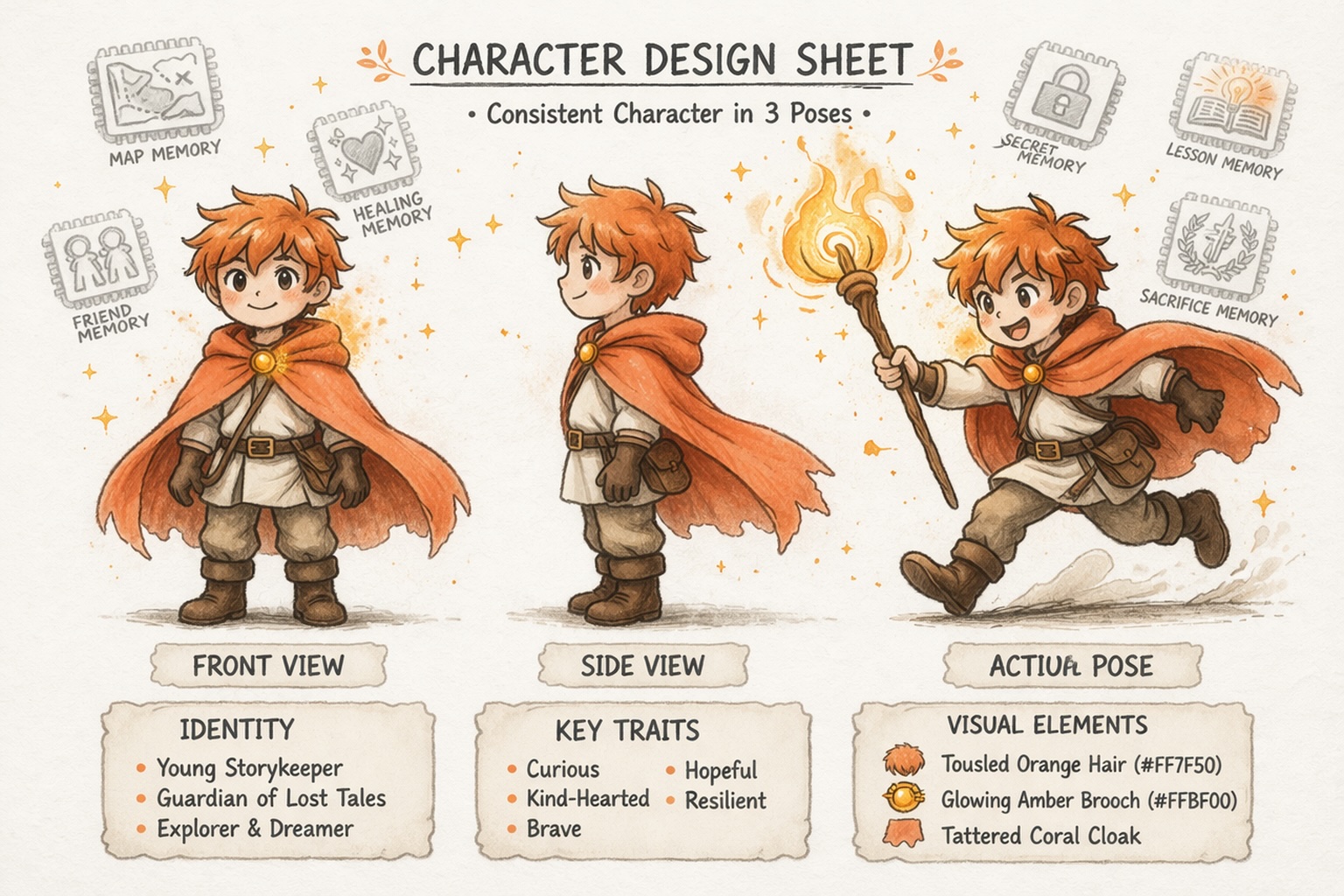
Développez des Univers, Pas Juste des Indications
Dépasser le Texte

Story AI ne devrait pas s'Arrêter après une Production
Les outils AI narrative traditionnels génèrent une fois et s'arrêtent là. Story321 est construit différemment. Il transforme l'AI narrative en un processus créatif continu où chaque étape s'appuie sur la précédente.
Commencez avec une Histoire
Commencez avec une seule idée et transformez-la en une histoire avec direction, structure et suffisamment de substance pour continuer à développer.
Continuez sans Recommencer
Au lieu de recommencer chaque fois, continuez à développer sur ce qui existe déjà. Continuez votre histoire en préservant le contexte et la dynamique.
Élargissez ce qui Fonctionne
Prenez une histoire prometteuse et développez-la. Ajoutez des arcs, des niveaux, des personnages et des détails d'univers sans perdre le cœur de ce qui fonctionne.
Transformez en Nouveaux Formats
Passer d'une histoire à un comic, une vidéo ou une expérience interactive. Avec story321, la création continue à évoluer plutôt que de s'arrêter à une simple production texte.
Conçu pour Différents Types de Créateurs
Quel que soit votre point de départ, story321 vous aide à développer.
Nouveaux Créateurs
Commencez sans pression. story321 rend l'AI narrative accessible, vous permettant de créer sans vous inquiéter de la structure ou de l'expérience.
Créateurs de Contenu
Avancez plus vite et produisez du contenu narratif à grande échelle. story321 transforme l'AI narrative en un moteur créatif fiable.
Constructeurs d'Univers
Concevez des personnages, narrations et systèmes qui évoluent. story321 vous aide à utiliser l'AI narrative pour des projets créatifs à long terme.
Comment story321 Change Story AI
Story AI devient plus puissant quand il est intégré dans un système. Ce système est story321.
| Features | La plupart des outils story AI | story321 |
|---|---|---|
Flux Créatif | Générer une fois | Construit continuellement |
Mémoire Narrative | Perdre le contexte | Maintenir la cohérence narrative |
Expansion de Formats | S'arrête là | Se développe au travers des formats |
Questions Fréquentes sur l'AI narrative
Qu'est-ce que story AI, et comment Story321 l'utilise ?
story AI est l'utilisation de l'IA pour vous aider à créer des histoires, des personnages et des univers partir d'une idée initiale. Story321 utilise story AI comme un système créatif, vous permettant de passer de concepts approximatifs à des histoires structurées et de continuer à construire plutôt que recommencer chaque fois.
Comment story AI m'aide à écrire des histoires plus vite ?
story AI vous aide à surmonter la page blanche en transformant des idées approximatives en directions narratives, drafts de scènes et fondations de personnages. Avec Story321, vous pouvez continuer à perfectionner et développer ce qui fonctionne déjà, ce qui rend le processus d'écriture plus rapide sans perdre votre contrôle créatif.
story AI peut-il garder les personnages et univers cohérents ?
Oui, mais seulement si la plateforme est conçue pour la continuité. Story321 aide story AI à rester cohérent au travers des personnages, intrigues et détails d'univers, vous permettant ainsi de développer un projet au fil du temps plutôt que générer des productions déconnectées.
Pourquoi choisir Story321 plutôt qu'un outil story AI générique ?
La plupart des outils story AI génèrent une réponse et s'arrêtent là. Story321 est conçu pour la création continue, vous aidant à développer une histoire en comics, vidéos et expériences interactives en gardant la même direction créative, personnages et logique d'univers.
Commencez votre Première Histoire avec story321
Vous n'avez pas besoin d'expérience. Vous n'avez pas besoin d'une idée parfaite. Vous avez juste besoin de commencer. Story AI vous donnera le commencement. story321 vous aidera à construire tout ce qui suit.