Story AI che Trasforma le Tue Idee in Mondi
Crea storie, costruisci personaggi e trasformali in fumetti, video o giochi — tutto con l'AI.
Parti da una semplice idea e trasformala in una storia, un mondo o qualcosa di ancora più grande. Con story321, la story AI diventa più di un semplice output—diventa un modo per creare, espandere e costruire.
Non Stai Usando la Story AI. Stai Creando con story321.
La maggior parte delle persone non ha problemi con le idee. Ha problemi a trasformare le idee in qualcosa di reale. Story321 cambia questo. Con la story AI integrata nel suo nucleo, story321 ti aiuta a:
Trasformare i pensieri in storie strutturate
Modellare e affinare la tua narrazione
Costruire qualcosa che cresce nel tempo
Dall'Idea all'Universo con story321
Ecco come appare la creazione quando la story AI funziona nel modo giusto.
Un'Idea Diventa una Storia
Inizia con una scintilla, un concetto o una premessa approssimativa. story321 ti aiuta a trasformarla in una storia strutturata su cui puoi effettivamente costruire.
Una Storia Diventa una Serie
Una volta che esiste la prima versione, puoi continuare. Prosegui gli archi narrativi, aggiungi capitoli e trasforma una storia in qualcosa di serializzato e sostenuto.
Una Serie Diventa un Mondo
Man mano che le storie si collegano, i personaggi si approfondiscono e gli ambienti si espandono. Ciò che è iniziato come una narrazione diventa un mondo con la sua logica, memoria e slancio.
Un Mondo Diventa Visivo e Interattivo
Story321 ti permette di trasformare quel mondo in fumetti, video ed esperienze interattive, così la creazione va oltre il testo in qualcosa che le persone possono vedere ed esplorare.
Story321 collega ogni passo. Non stai solo generando contenuti. Stai costruendo qualcosa che cresce.
Un Nuovo Modo di Creare con la Story AI
Story321 trasforma il funzionamento della story AI—passando dalla semplice generazione alla creazione continua.
Crea Storie che Si Evolvono
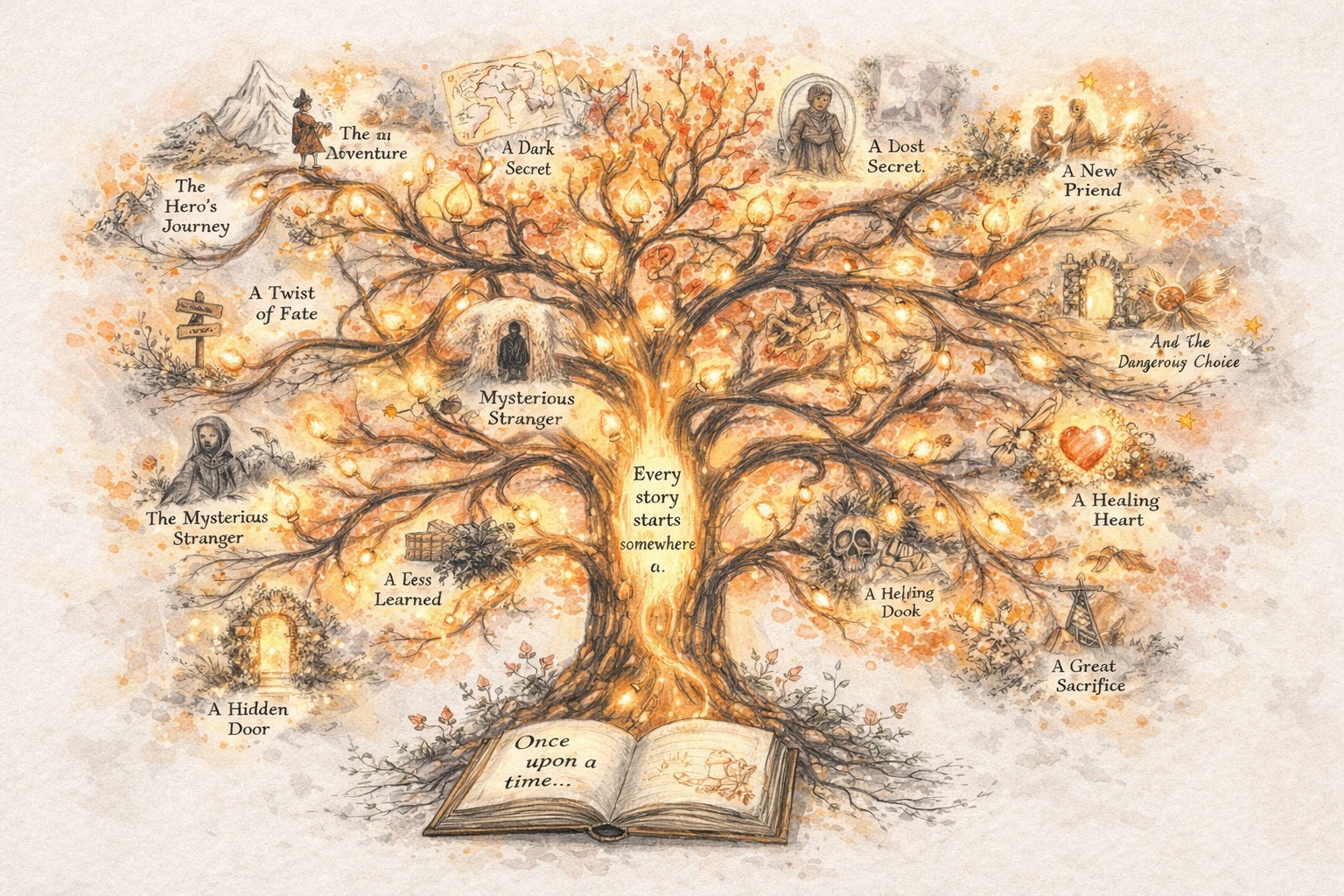
Costruisci Personaggi che Rimangono Coerenti
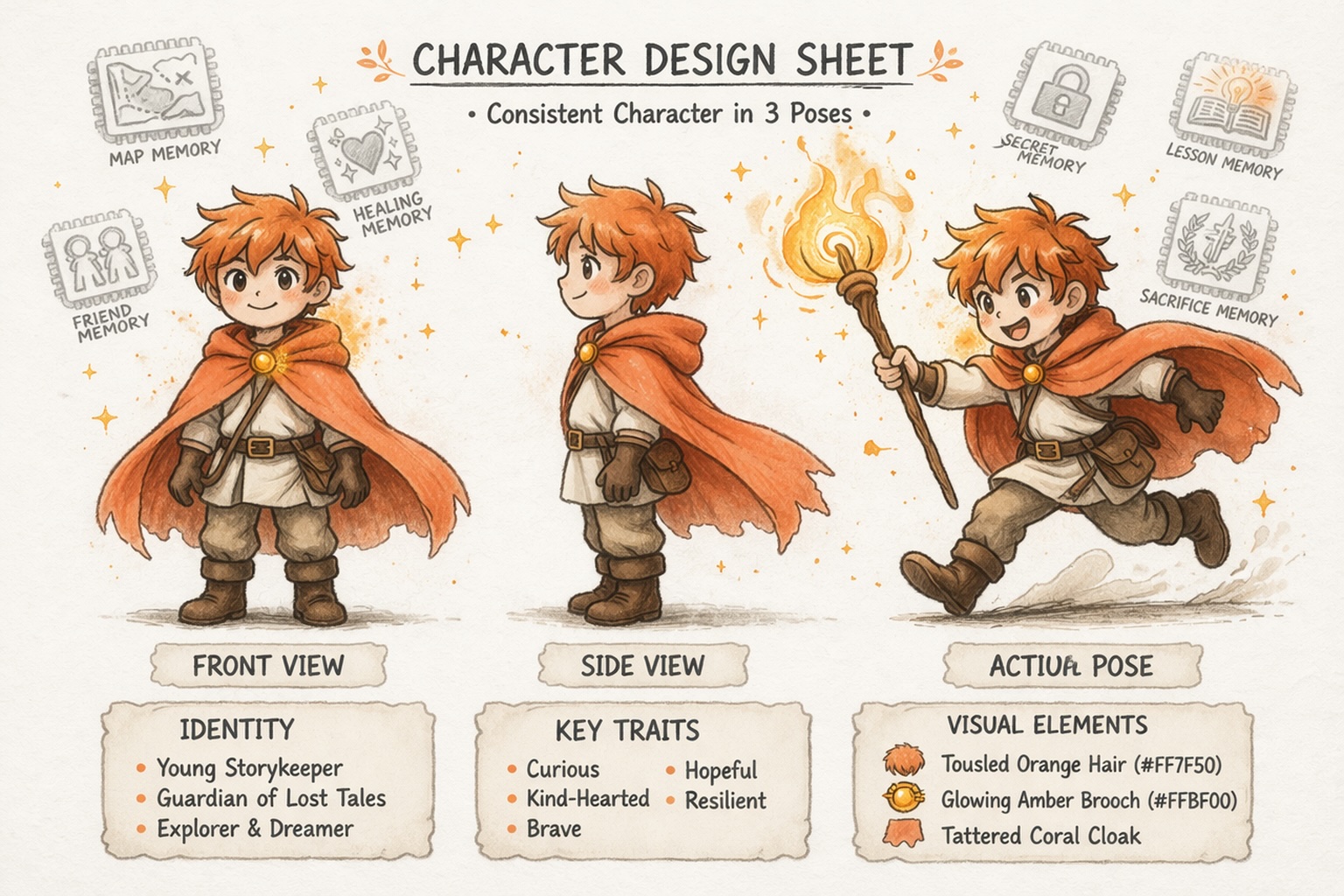
Sviluppa Mondi, Non Solo Prompt
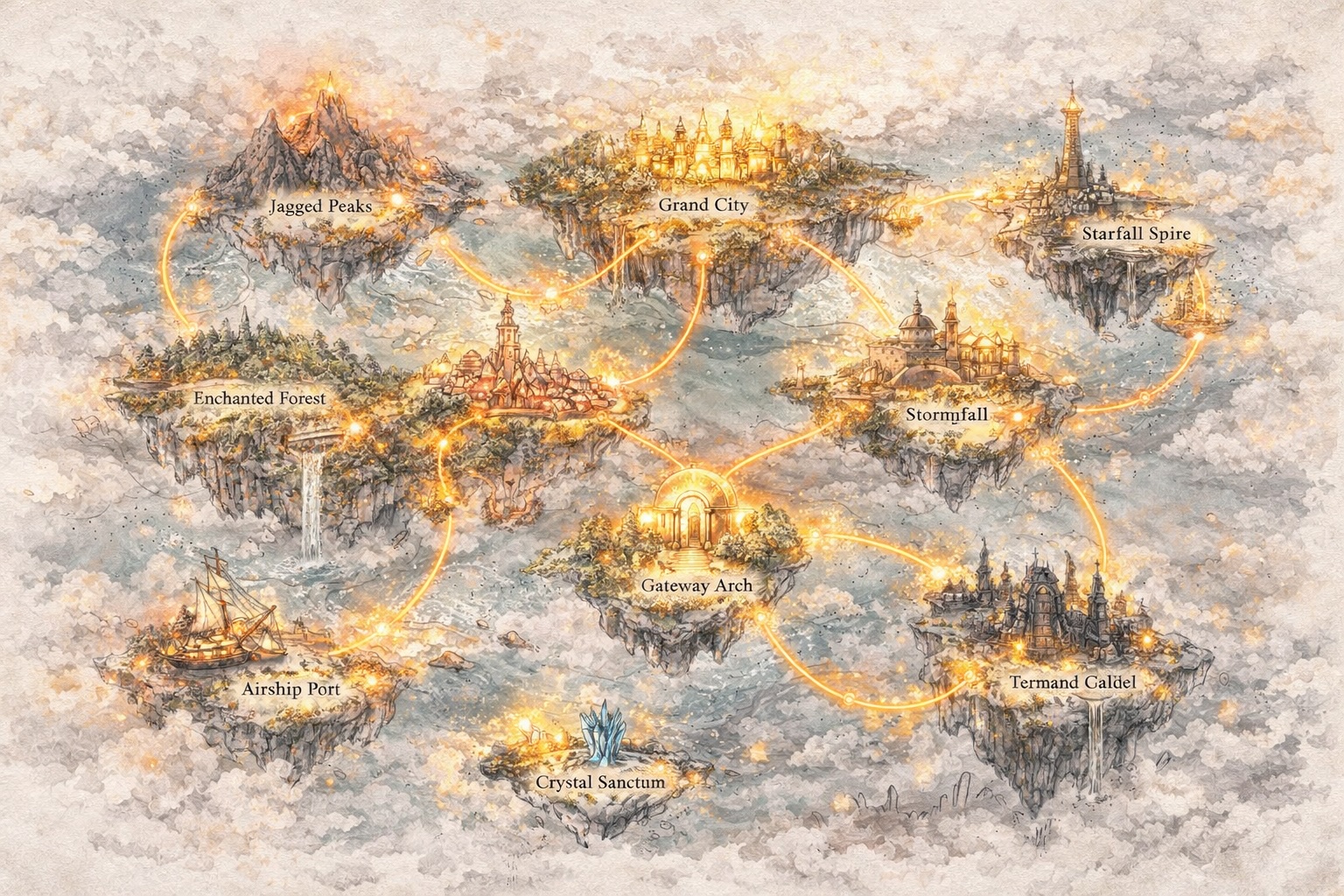
Vai Oltre il Testo

La Story AI Non Dovrebbe Fermarsi Dopo un Solo Output
I tradizionali strumenti di story AI generano una volta e si fermano lì. Story321 è costruito diversamente. Trasforma la story AI in un processo creativo continuo in cui ogni passo si basa sul precedente.
Inizia con una Storia
Parti da una singola idea e modellala in una storia con direzione, struttura e sostanza sufficiente per continuare a svilupparla.
Continua Senza Resettare
Invece di ricominciare ogni volta, continua a costruire su ciò che già esiste. Prosegui la tua storia preservando il contesto e lo slancio.
Espandi Ciò che Funziona
Prendi una storia promettente e falla crescere. Aggiungi archi narrativi, livelli, personaggi e dettagli del mondo senza perdere il nucleo di ciò che l'ha resa efficace.
Trasforma in Nuovi Formati
Passa dalla storia al fumetto, al video o all'esperienza interattiva. Con story321, la creazione continua a evolversi invece di terminare con un singolo output testuale.
Costruito per Diversi Tipi di Creatori
Indipendentemente dal tuo punto di partenza, story321 ti aiuta a crescere.
Nuovi Creatori
Inizia senza pressioni. story321 rende la story AI accessibile, così puoi creare senza preoccuparti della struttura o dell'esperienza.
Creatori di Contenuti
Muoviti più velocemente e produci contenuti guidati dalla storia su larga scala. story321 trasforma la story AI in un motore creativo affidabile.
Costruttori di Mondi
Progetta personaggi, narrazioni e sistemi che si evolvono. story321 ti aiuta a usare la story AI per progetti creativi a lungo termine.
Perché story321 Cambia la Story AI
La story AI diventa più potente quando fa parte di un sistema. Quel sistema è story321.
| Features | La maggior parte degli strumenti di story AI | story321 |
|---|---|---|
Flusso Creativo | Genera una volta | Costruisce in continuazione |
Memoria Narrativa | Perde il contesto | Mantiene la coerenza narrativa |
Espansione dei Formati | Si ferma lì | Si espande tra i formati |
Domande Frequenti sulla story AI
Cos'è la story AI e come la usa Story321?
La story AI è l'uso dell'AI per aiutarti a creare storie, personaggi e mondi partendo da un'idea iniziale. Story321 usa la story AI come un sistema creativo, così puoi passare da concetti approssimativi a storie strutturate e continuare a costruire invece di ricominciare ogni volta.
Come mi aiuta la story AI a scrivere storie più velocemente?
La story AI ti aiuta a superare la pagina bianca trasformando idee vaghe in direzioni narrative, bozze di scene e basi per i personaggi. Con Story321, puoi continuare ad affinare ed estendere ciò che già funziona, rendendo il processo di scrittura più veloce senza perdere il controllo creativo.
La story AI può mantenere personaggi e mondi coerenti?
Sì, ma solo se la piattaforma è costruita per la continuità. Story321 aiuta la story AI a rimanere coerente tra personaggi, trame e dettagli del mondo, così puoi far crescere un progetto nel tempo invece di generare output scollegati.
Perché scegliere Story321 invece di uno strumento generico di story AI?
La maggior parte degli strumenti di story AI genera una risposta e si ferma lì. Story321 è costruito per la creazione continua, aiutandoti a espandere una storia in fumetti, video ed esperienze interattive mantenendo la stessa direzione creativa, personaggi e logica del mondo.
Inizia la Tua Prima Storia con story321
Non ti serve esperienza. Non ti serve un'idea perfetta. Ti serve solo iniziare. La story AI ti darà l'inizio. story321 ti aiuterà a costruire tutto ciò che viene dopo.