Story AI Die Je Ideeën in Werelden Verandert
Creëer verhalen, bouw personages en zet ze om in strips, video's of games – allemaal met AI.
Begin met een simpel idee en maak er een verhaal, een wereld of iets nog groters van. Met story321 wordt story ai meer dan alleen output – het wordt een manier om te creëren, uit te breiden en op te bouwen.
Je Gebruikt Geen Story AI. Je Creëert met story321.
De meeste mensen worstelen niet met ideeën. Ze worstelen met het omzetten van ideeën in iets tastbaars. Story321 verandert dat. Met story ai in de kern helpt story321 je om:
Gedachten om te zetten in gestructureerde verhalen
Je verhaal vorm te geven en te verfijnen
Iets op te bouwen dat met de tijd groeit
Van Idee naar Universum met story321
Zo ziet creatie eruit wanneer story ai op de juiste manier werkt.
Een Idee Wordt een Verhaal
Begin met een vonk, een concept of een ruwe premisse. story321 helpt je het om te zetten in een gestructureerd verhaal waar je echt op kunt bouwen.
Een Verhaal Wordt een Serie
Zodra de eerste versie bestaat, kun je doorgaan. Verleng verhaallijnen, voeg hoofdstukken toe en laat één verhaal uitgroeien tot iets geserialiseerds en duurzaams.
Een Serie Wordt een Wereld
Naarmate verhalen zich verbinden, krijgen personages meer diepgang en settings breiden uit. Wat begon als een verhaal wordt een wereld met een eigen logica, geheugen en momentum.
Een Wereld Wordt Visueel en Interactief
Story321 laat je die wereld transformeren in strips, video's en interactieve ervaringen, zodat creatie verder gaat dan tekst en iets wordt wat mensen kunnen zien en verkennen.
Story321 verbindt elke stap. Je genereert niet alleen content. Je bouwt iets op dat groeit.
Een Nieuwe Manier om te Creëren met Story AI
Story321 transformeert hoe story ai werkt – van simpele generatie naar continue creatie.
Creëer Verhalen Die Evolueren
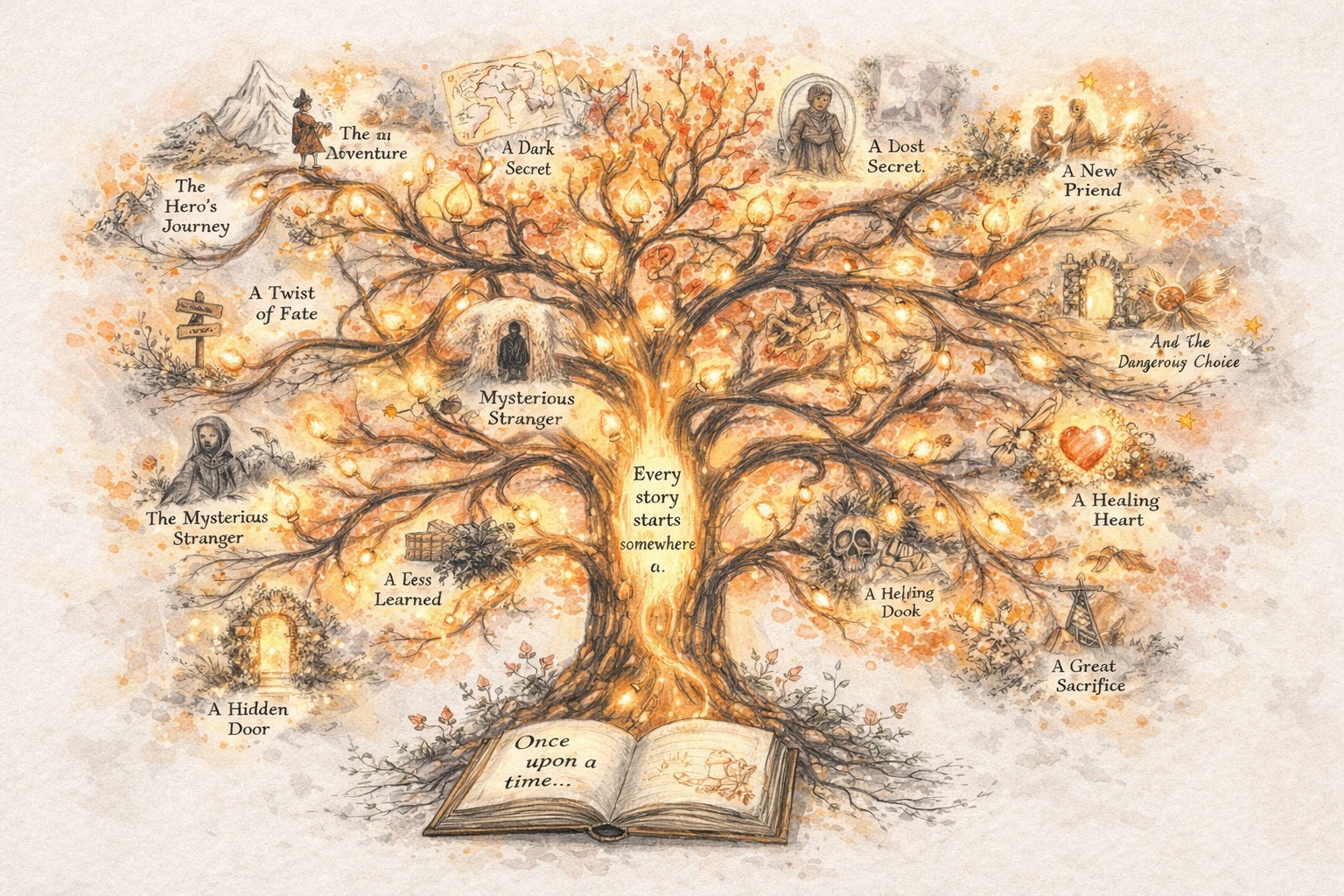
Bouw Personages Die Consistent Blijven
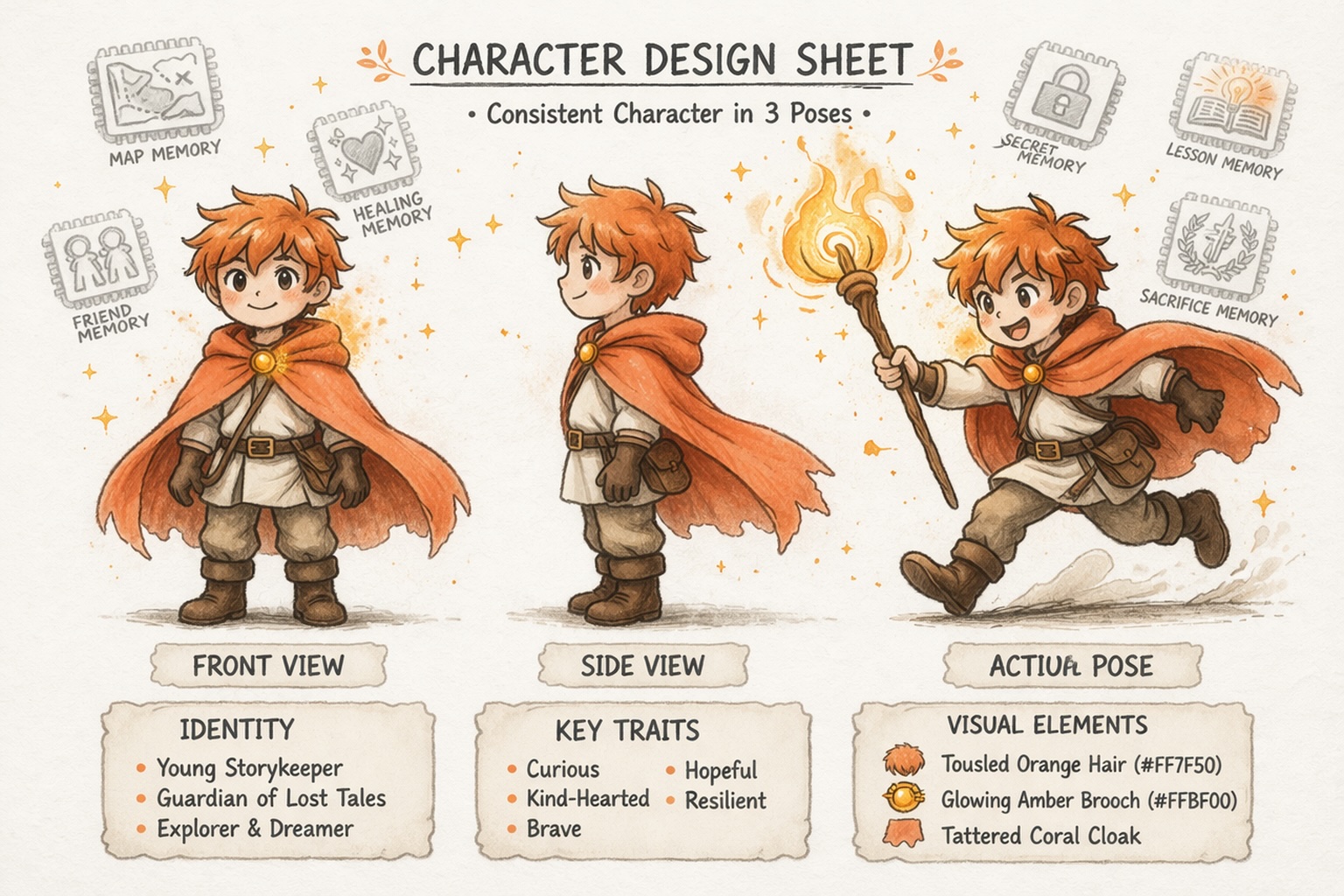
Ontwikkel Werelden, Niet Alleen Prompts
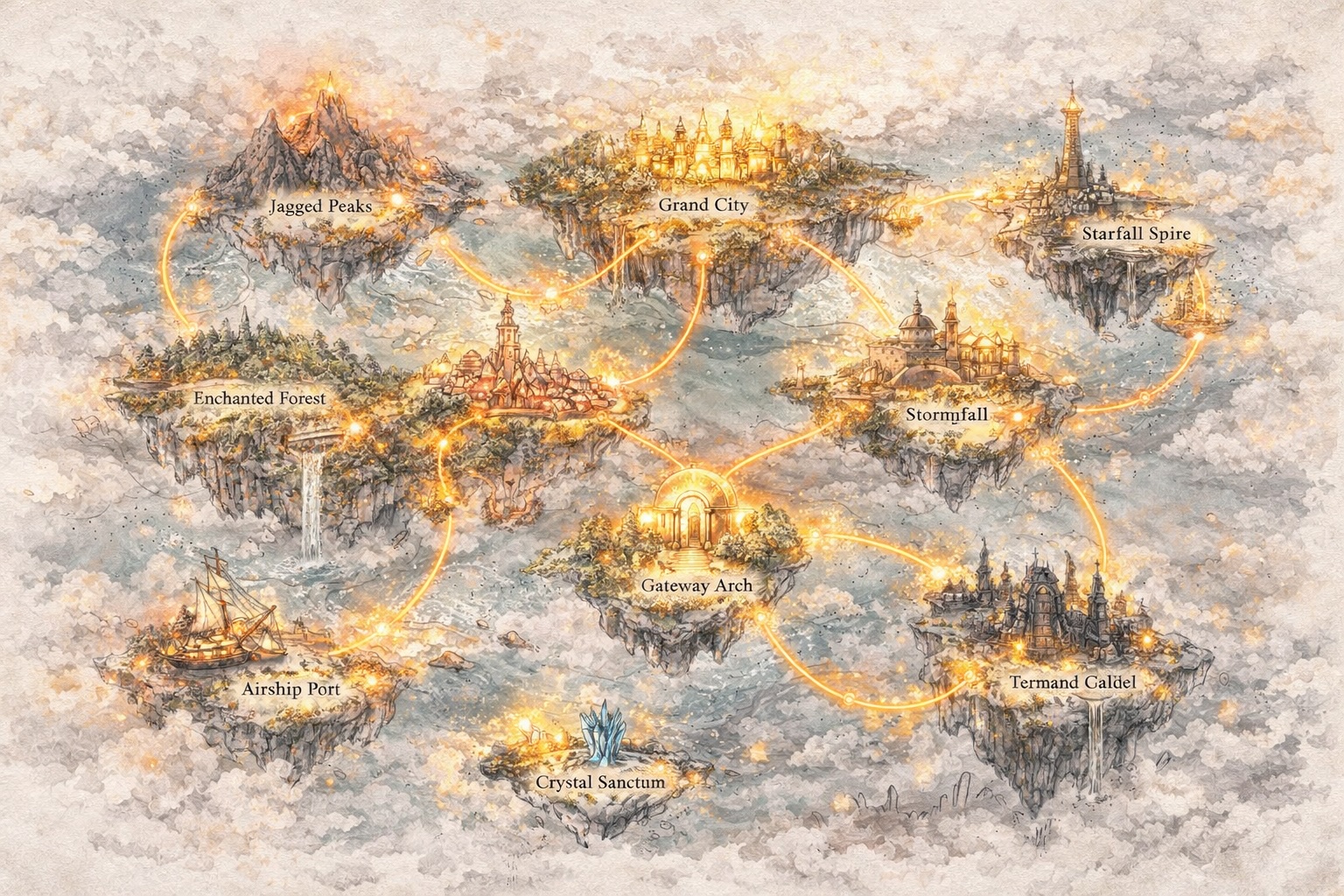
Ga Voorbij Tekst

Story AI Zou Niet Moeten Stoppen Na Eén Output
Traditionele story ai tools genereren één keer en stoppen daar. Story321 is anders opgebouwd. Het verandert story ai in een continu creatief proces waarbij elke stap voortbouwt op de vorige.
Begin met een Verhaal
Start met één idee en vorm het tot een verhaal met richting, structuur en voldoende inhoud om verder te ontwikkelen.
Ga Door Zonder Opnieuw te Beginnen
In plaats van elke keer opnieuw te beginnen, blijf je bouwen op wat er al is. Zet je verhaal voort terwijl je context en momentum behoudt.
Breid Uit Wat Werkt
Neem een veelbelovend verhaal en laat het groeien. Voeg verhaallijnen, lagen, personages en werelddetails toe zonder de kern te verliezen die het liet werken.
Transformeer naar Nieuwe Formaten
Ga van verhaal naar strip, video of interactieve ervaring. Met story321 blijft creatie evolueren in plaats van te eindigen bij één tekstoutput.
Gebouwd voor Verschillende Soorten Creators
Wat je startpunt ook is, story321 helpt je groeien.
Nieuwe Creators
Start zonder druk. story321 maakt story ai toegankelijk, zodat je kunt creëren zonder je zorgen te maken over structuur of ervaring.
Content Creators
Werk sneller en produceer verhaalgedreven content op grote schaal. story321 verandert story ai in een betrouwbare creatieve motor.
Wereldbouwers
Ontwerp personages, verhalen en systemen die evolueren. story321 helpt je story ai te gebruiken voor langetermijn creatieve projecten.
Waarom story321 Story AI Verandert
Story ai wordt krachtiger wanneer het deel uitmaakt van een systeem. Dat systeem is story321.
| Features | De meeste story ai tools | story321 |
|---|---|---|
Creatieve Flow | Genereer één keer | Bouwt continu door |
Narratief Geheugen | Verliest context | Houdt narratieve consistentie |
Formaat Uitbreiding | Stopt daar | Breidt uit over formaten |
Veelgestelde Vragen over story ai
Wat is story ai, en hoe gebruikt Story321 het?
story ai is het gebruik van AI om je te helpen verhalen, personages en werelden te creëren vanuit een initieel idee. Story321 gebruikt story ai als een creatief systeem, zodat je van ruwe concepten naar gestructureerde verhalen kunt gaan en kunt blijven bouwen in plaats van elke keer opnieuw te beginnen.
Hoe helpt story ai me sneller verhalen te schrijven?
story ai helpt je voorbij de lege pagina te komen door losse ideeën om te zetten in verhaalrichtingen, scèneconcepten en personagefundamenten. Met Story321 kun je blijven verfijnen en uitbreiden wat al werkt, wat het schrijfproces versnelt zonder je creatieve controle te verliezen.
Kan story ai personages en werelden consistent houden?
Ja, maar alleen als het platform is gebouwd voor continuïteit. Story321 helpt story ai consistent te blijven over personages, verhaallijnen en werelddetails heen, zodat je een project in de tijd kunt laten groeien in plaats van losstaande outputs te genereren.
Waarom Story321 kiezen in plaats van een generieke story ai tool?
De meeste story ai tools genereren één antwoord en stoppen daar. Story321 is gebouwd voor continue creatie, het helpt je een verhaal uit te breiden naar strips, video's en interactieve ervaringen terwijl je dezelfde creatieve richting, personages en wereldlogica behoudt.
Start Je Eerste Verhaal met story321
Je hebt geen ervaring nodig. Je hebt geen perfect idee nodig. Je hoeft alleen maar te beginnen. Story ai geeft je het begin. story321 helpt je alles op te bouwen wat daarna komt.