将您的想法变为世界的Story AI
创作故事,构建角色,并将它们转化为漫画、视频或游戏——这一切都借助AI完成。
从一个简单的想法开始,将其变成一个故事、一个世界,甚至更宏大的事物。有了story321,故事AI不仅仅是输出——它成为一种创造、扩展和构建的方式。
您不是在用故事AI。您是在用story321创作。
大多数人的困扰不在于想法,而在于如何将想法变为现实。Story321改变了这一点。其核心内置的故事AI,帮助您:
将想法转化为结构化的故事
塑造并完善您的叙事
构建一个能随时间成长的作品
从想法到宇宙,用story321实现
这就是当故事AI以正确方式工作时,创作应有的样子。
一个想法变成一个故事
从一个火花、一个概念或一个粗略的前提开始。story321帮助您将其转化为一个结构化的、可供实际构建的故事。
一个故事变成一个系列
一旦第一个版本存在,您就可以继续下去。延续剧情线,添加章节,将一个故事发展成连载且持续的作品。
一个系列变成一个世界
随着故事相互连接,角色深化,场景扩展。始于一个叙事的事物,变成了一个拥有自身逻辑、记忆和动力的世界。
一个世界变得可视化和可交互
Story321让您将那个世界转化为漫画、视频和互动体验,使创作超越文本,成为人们可以看见和探索的东西。
Story321连接每一步。您不仅仅是在生成内容。您是在构建一个能不断成长的事物。
用故事AI创作的新方式
Story321改变了故事AI的工作方式——从简单的生成转向持续的创作。
创作不断演进的故事
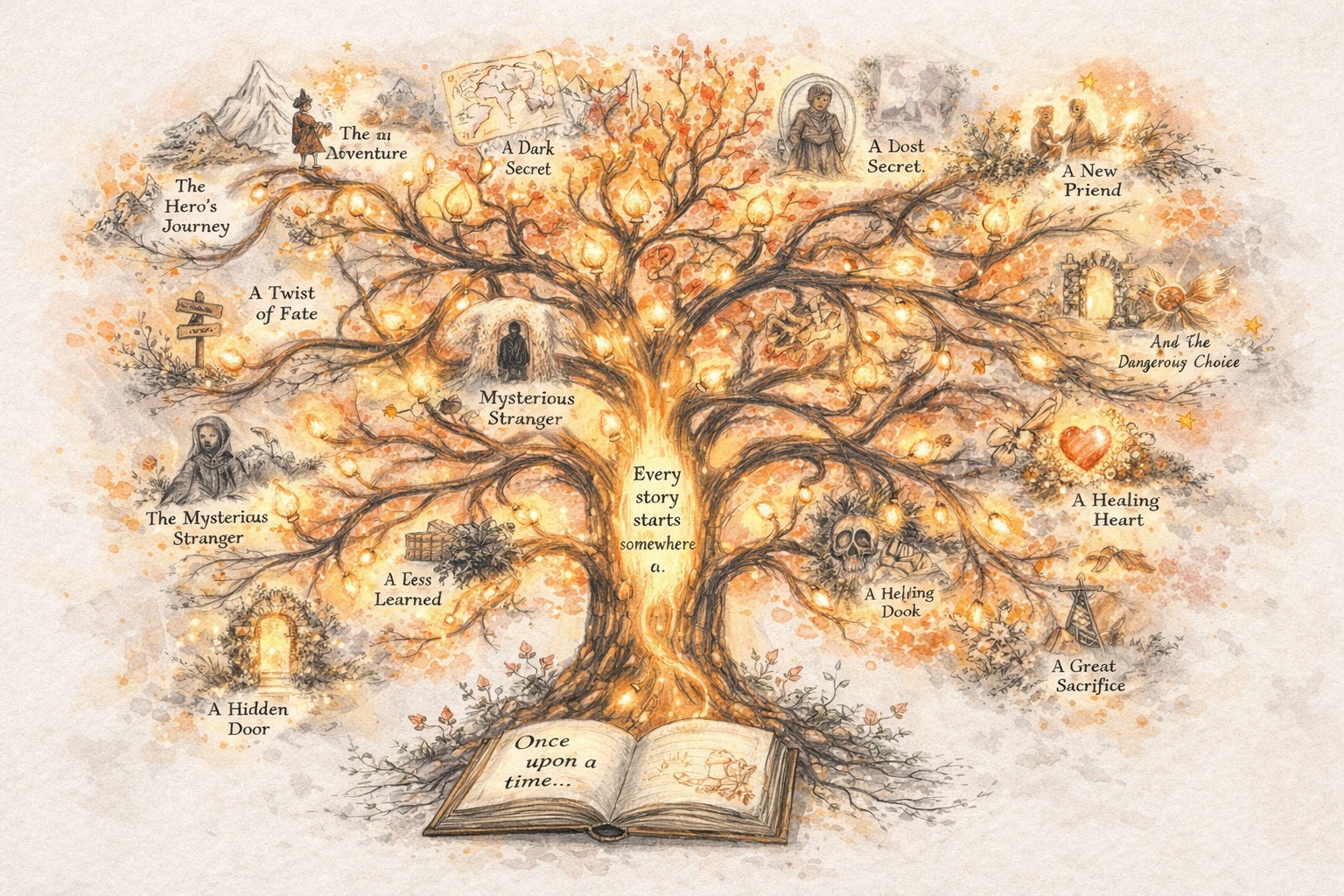
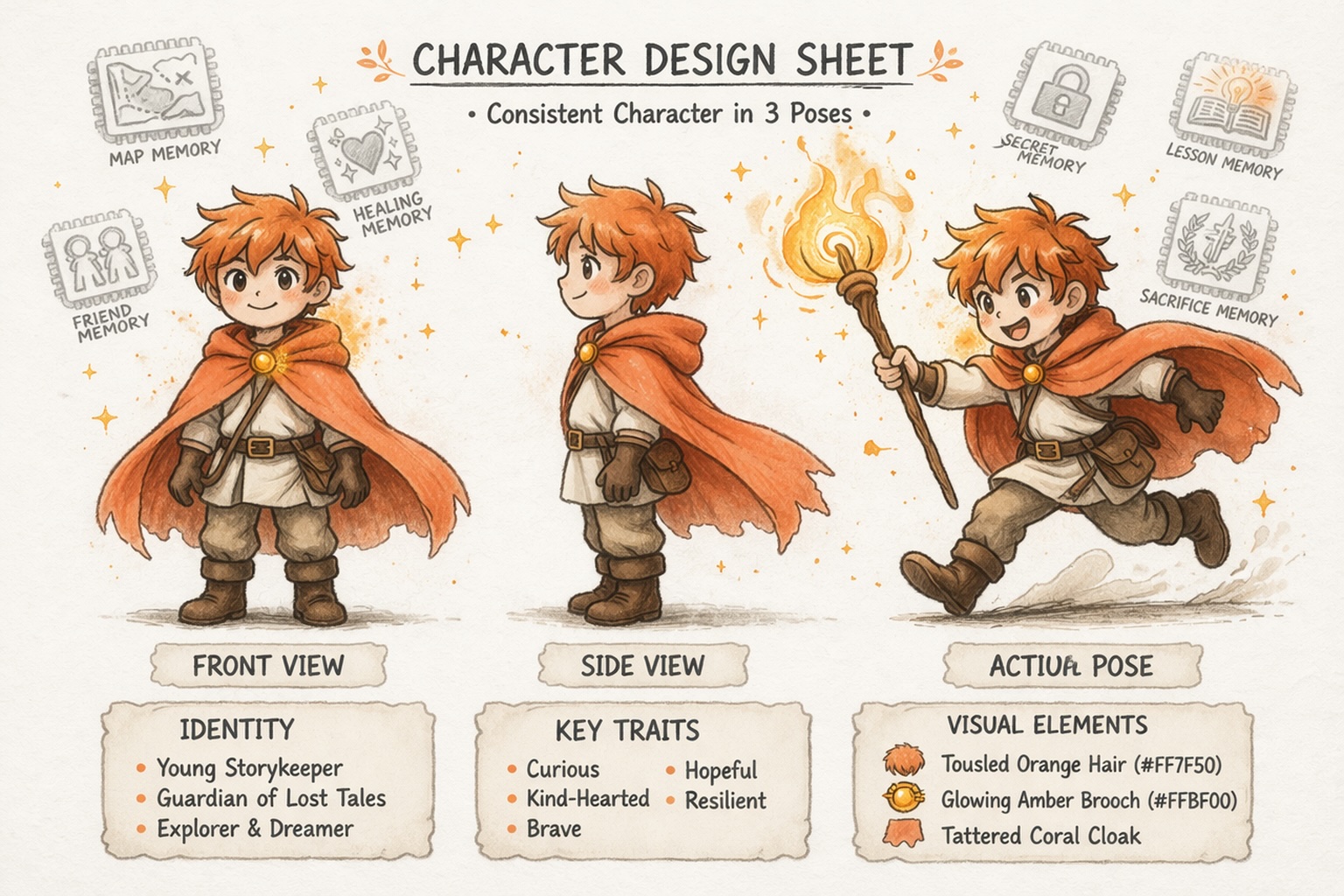
构建保持一致的的角色
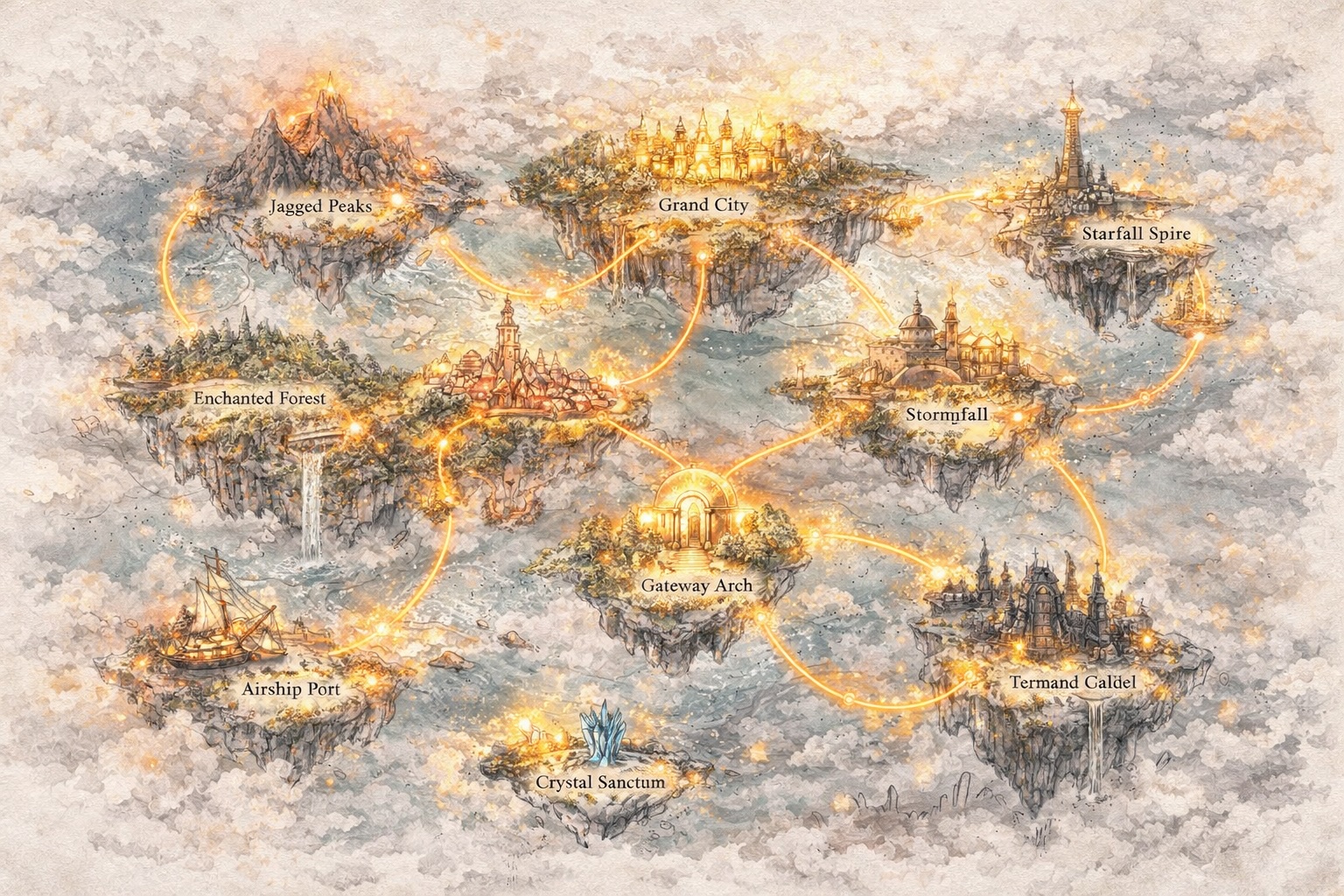
发展世界,而不仅仅是提示
超越文本

故事AI不应在一次输出后就停止
传统的故事AI工具生成一次就结束了。Story321的设计不同。它将故事AI转变为一个持续的创作过程,每一步都建立在之前的基础上。
从一个故事开始
从一个简单的想法开始,将其塑造成一个有方向、有结构、有足够内容可供持续发展的故事。
无需重置,持续创作
与其每次都从头开始,不如在已有基础上继续构建。延续您的故事,同时保持上下文和动力。
扩展有效的内容
抓住一个有潜力的故事并向外扩展。添加剧情线、层次、角色和世界细节,而不丢失其成功的核心。
转化为新格式
从故事转向漫画、视频或互动体验。有了story321,创作不断演进,而不是止步于单一的文本输出。
为不同类型的创作者打造
无论您的起点如何,story321都能帮助您成长。
新手创作者
无压力地开始。story321让故事AI变得触手可及,让您可以无忧创作,无需担心结构或经验。
内容创作者
更快地创作,大规模产出故事驱动的内容。story321将故事AI变成一个可靠的创意引擎。
世界构建者
设计能不断演进的角色、叙事和系统。story321帮助您将故事AI用于长期的创意项目。
为什么story321改变了故事AI
当故事AI成为一个系统的一部分时,它会变得更强大。那个系统就是story321。
| Features | 大多数故事AI工具 | story321 |
|---|---|---|
创意流程 | 生成一次 | 持续构建 |
叙事记忆 | 丢失上下文 | 保持叙事一致性 |
格式扩展 | 止步于此 | 跨格式扩展 |
关于故事AI的常见问题
什么是故事AI,Story321如何使用它?
故事AI是利用AI帮助您从初始想法创建故事、角色和世界。Story321将故事AI作为一个创意系统使用,让您可以从粗略的概念发展到结构化的故事,并持续构建,而不是每次都从头开始。
故事AI如何帮助我更快地写故事?
故事AI通过将松散的想法转化为故事方向、场景草稿和角色基础,帮助您跨越空白页的障碍。借助Story321,您可以持续完善和扩展已有的有效内容,从而在不失去创意控制的情况下加快写作过程。
故事AI能保持角色和世界的一致性吗?
可以,但前提是平台是为连续性而构建的。Story321帮助故事AI在角色、故事情节和世界细节上保持一致,让您可以随时间发展一个项目,而不是生成互不关联的输出。
为什么选择Story321而不是通用的故事AI工具?
大多数故事AI工具生成一次响应就结束了。Story321是为持续创作而构建的,帮助您将故事扩展为漫画、视频和互动体验,同时保持相同的创意方向、角色和世界逻辑。