Story AI الذي يحول أفكارك إلى عوالم
أنشئ قصصًا، ابني شخصيات، وتحويلها إلى رسوم هزلية، فيديوهات، أو ألعاب — كل ذلك بالذكاء الاصطناعي.
ابدأ بفكرة بسيطة وتحولها إلى قصة، عالم، أو شيء أكبر. مع story321، Story AI يصبح أكثر من مجرد إنتاج — يصبح طريقة للإبداع، التوسيع، والبناء.
أنت لا تستخدم Story AI. أنت تُبدع مع story321.
معظم الناس لا يعانون من الأفكار. يعانون من تحويل الأفكار إلى شيء حقيقي. Story321 يغير ذلك. مع Story AI المدمج في أساسه، story321 يساعدك في:
تحويل الأفكار إلى قصص منظّمة
تشكيل وصقل روايتك
بناء شيء يتطور عبر الزمن
من الفكرة إلى الكون مع story321
هذا هو شكل الإبداع عندما يعمل Story AI بالطريقة الصحيحة.
الفكرة تصبح قصة
ابدأ بومضة، مفهوم، أو مقدمات أولية. story321 يساعدك في تحويلها إلى قصة منظّمة يمكنك البناء عليها فعليًا.
القصة تصبح سلسلة
بمجرد وجود النسخة الأولى، يمكنك الاستمرار. تواصل في الأحداث، أضف فصولًا، وطور القصة الواحدة إلى شيء متسلسل ودائم.
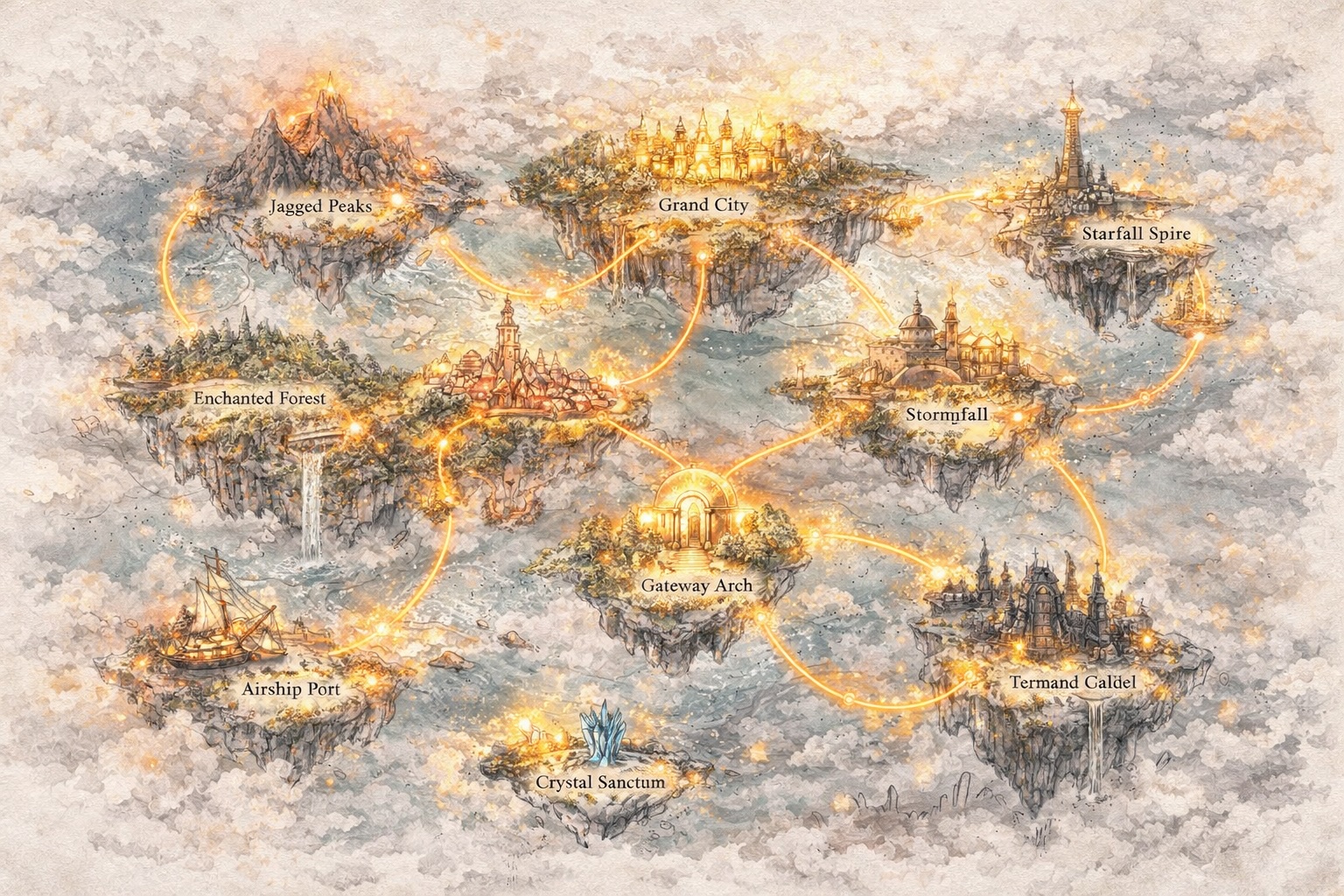
السلسلة تصبح عالمًا
عندما تتصل القصص، تتعمق الشخصيات ويتوسع العالم. ما بدأ كرواية يصبح عالمًا بمنطق خاص، ذاكرة، وحركة.
العالم يصبح مرئيًا وتفاعليًا
Story321 يسمح لك تحويل هذا العالم إلى رسوم هزلية، فيديوهات، وتجارب تفاعلية، لذا ينتقل الإبداع من النص إلى شيء يمكن للناس رؤيته واستكشافه.
Story321 يربط كل خطوة. أنت لا تولد محتوى فقط. أنت تبني شيء يتطور.
طريقة جديدة للإبداع مع Story AI
Story321 يحول طريقة عمل Story AI — من التوليد البسيط إلى الإبداع المستمر.
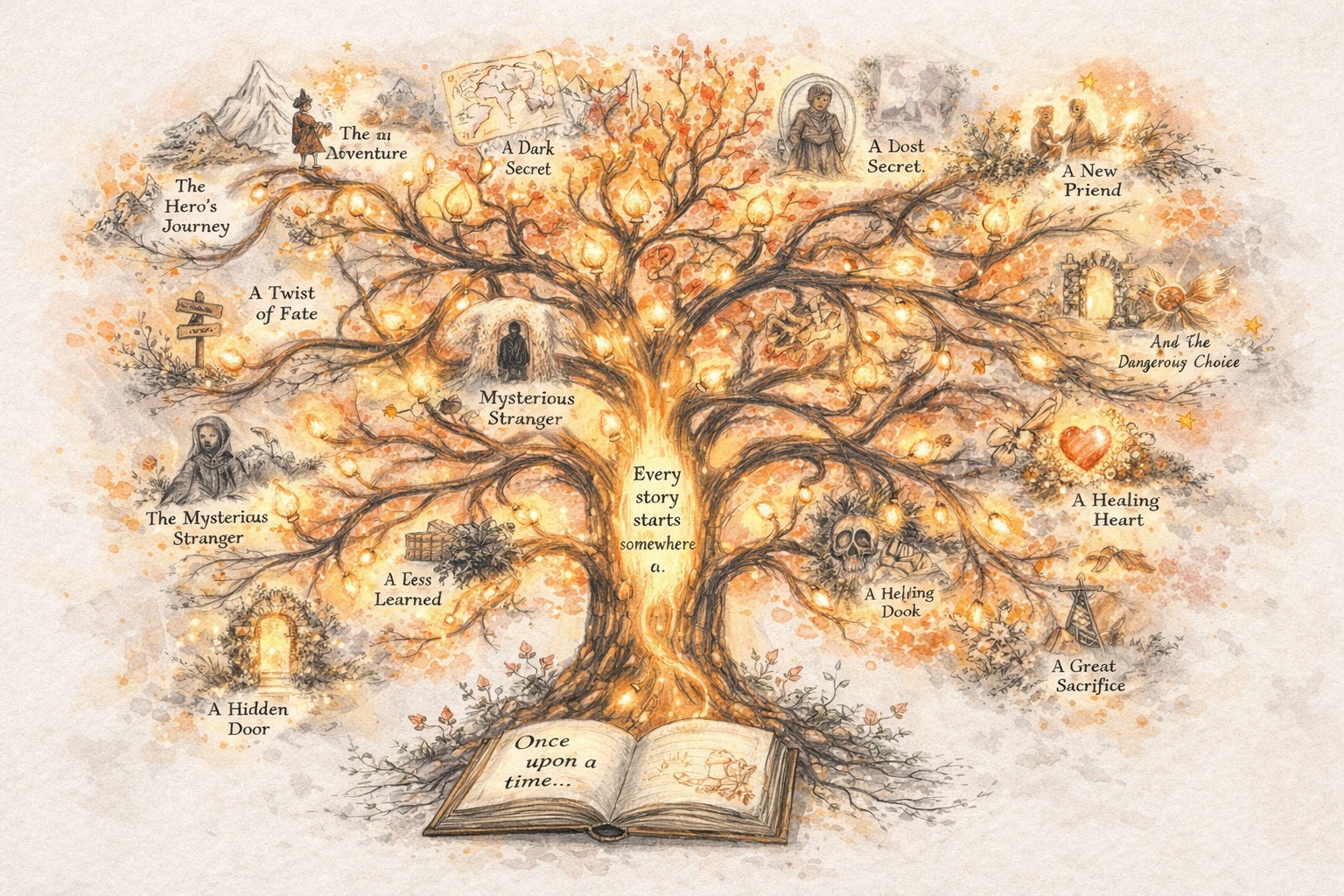
أنشئ قصصًا تتطور
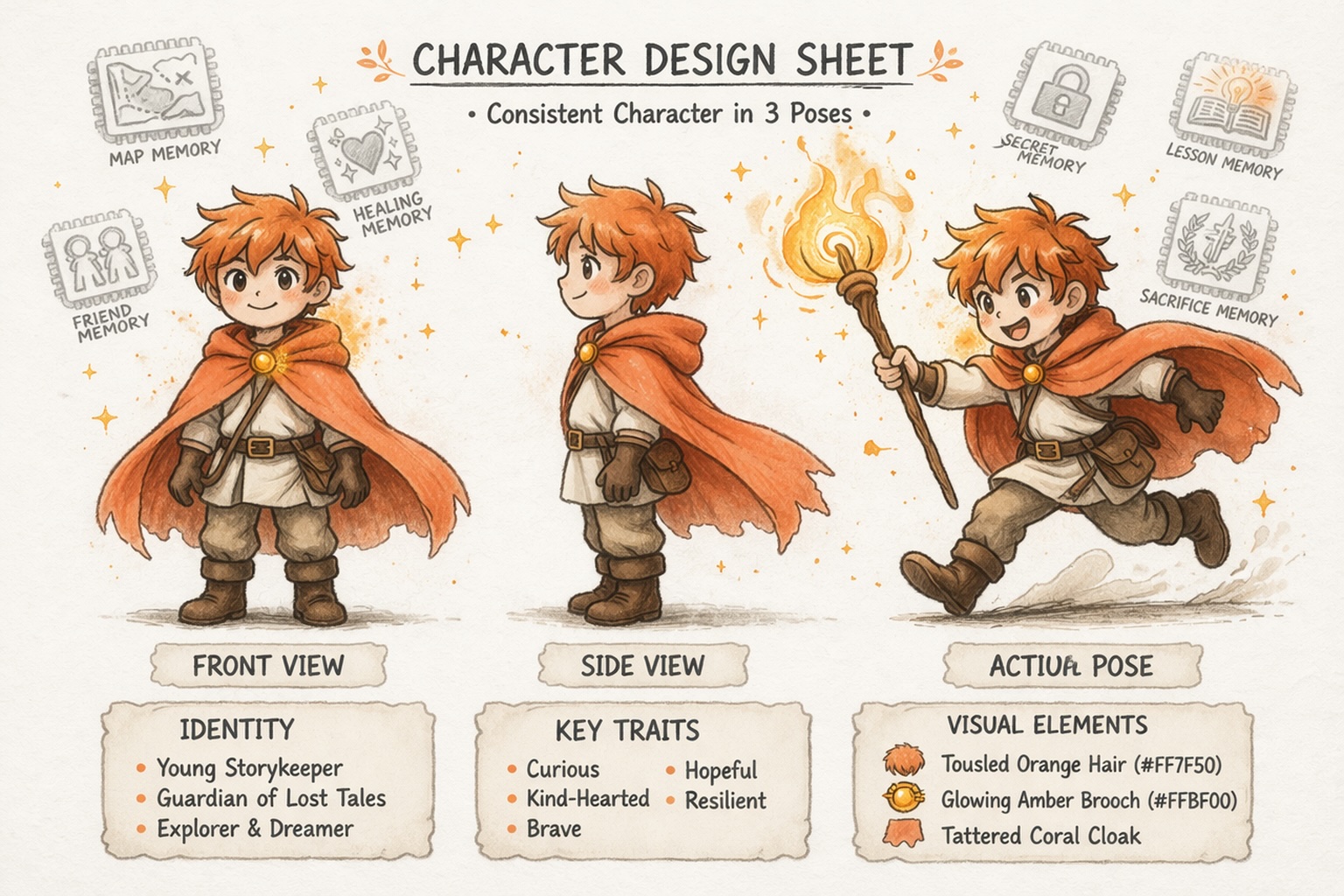
ابني شخصيات تبقى متناسقة
طور عوالم، ليس فقط prompts
تجاوز النص

Story AI لا يجب أن يتوقف بعد نتيجة واحدة
أدوات Story AI التقليدية تولد مرة وتتوقف هناك. Story321 مبني بشكل مختلف. يحول Story AI إلى عملية إبداعية مستمرة حيث كل خطوة تبنى على السابقة.
ابدأ بقصة
ابدأ بفكرة واحدة وشكلها إلى قصة ذات اتجاه، هيكل، ومادة كافية للتطوير المستمر.
تواصل دون إعادة ضبط
بدلًا من البدء من جديد كل مرة، استمر في البناء من ما موجود بالفعل. تواصل قصتك مع الحفاظ على السياق والحركة.
وسع ما يعمل
خذ قصة واعدة وتوسعها. أضف خطوطًا، طبقات، شخصيات، وتفاصيل عالمية دون فقدان جوهر ما جعلها تعمل.
تحول إلى صيغ جديدة
انتقل من قصة إلى رسوم هزلية، فيديو، أو تجربة تفاعلية. مع story321، الإبداع يستمر في التطور بدلًا من الانتهاء عند إنتاج نص واحد.
مبني لمبدعين مختلفين
بغض النظر عن نقطة بدايتك، story321 يساعدك على النمو.
المبدعين الجدد
ابدأ دون ضغط. story321 يجعل Story AI متاحًا، لذا يمكنك الإبداع دون القلق حول الهيكل أو الخبرة.
مبدعي المحتوى
تحرك بسرعة وأنتج محتوى قائم على القصة بكميات كبيرة. story321 يحول Story AI إلى محرك إبداعي موثوق.
بناة العوالم
صمم شخصيات، روايات، وأنظمة تتطور. story321 يساعدك في استخدام Story AI للمشاريع الإبداعية طويلة الأمد.
لماذا يتغير Story AI مع story321
Story AI يصبح أكثر قوة عندما يكون جزءًا من نظام. هذا النظام هو story321.
| Features | معظم أدوات Story AI | story321 |
|---|---|---|
الطريقة الإبداعية | توليد مرة واحدة | يبني بشكل مستمر |
ذاكرة الرواية | يفقد السياق | يحافظ على تناسق الرواية |
توسيع الصيغ | يتوقف هنا | يتوسع عبر الصيغ |
أسئلة متكررة حول Story AI
ما هو Story AI، وكيف يستخدمه Story321؟
Story AI هو استخدام الذكاء الاصطناعي لمساعدتك في إنشاء قصص، شخصيات، وعوالم من فكرة أولية. Story321 يستخدم Story AI كنظام إبداعي، لذا يمكنك الانتقال من المفاهيم الأولية إلى قصص منظّمة والاستمرار في البناء بدلًا من البدء من جديد كل مرة.
كيف يساعدني Story AI في كتابة قصص بشكل أسرع؟
Story AI يساعدك في تجاوز الصفحة الفارغة عن طريق تحويل الأفكار العامة إلى اتجاهات قصص، مسودات للمشاهد، وأساسيات للشخصيات. مع Story321، يمكنك الاستمرار في الصقل والتوسيع لما يعمل بالفعل، مما يجعل عملية الكتابة أسرع دون فقدان سيطرتك الإبداعية.
هل يمكن لStory AI الحفاظ على تناسق الشخصيات والعوالم؟
نعم، ولكن فقط إذا كانت المنصة مبنية للاستمرارية. Story321 يساعد Story AI في البقاء متناسقًا عبر الشخصيات، خطوط القصة، وتفاصيل العالم، لذا يمكنك تنمية مشروع عبر الزمن بدلًا من توليد نتائج غير متصلة.
لماذا تختار Story321 بدلًا من أداة Story AI عامة؟
معظم أدوات Story AI تولد ردًا واحدًا وتتوقف هناك. Story321 مبني للإبداع المستمر، يساعدك في توسيع قصة إلى رسوم هزلية، فيديوهات، وتجارب تفاعلية مع الحفاظ على نفس الاتجاه الإبداعي، الشخصيات، ومنطق العالم.
ابدأ قصتك الأولى مع story321
لا تحتاج خبرة. لا تحتاج فكرة مثالية. تحتاج فقط البدء. Story AI سيمنحك البداية. story321 سيساعدك في بناء كل ما يأتي بعد ذلك.