AI Cerita yang Mengubah Ide Anda Menjadi Dunia
Buat cerita, bangun karakter, dan ubah menjadi komik, video, atau game — semuanya dengan AI.
Mulai dari ide sederhana dan ubah menjadi cerita, dunia, atau sesuatu yang lebih besar. Dengan story321, AI cerita menjadi lebih dari sekadar keluaran — ia menjadi cara untuk menciptakan, memperluas, dan membangun.
Anda Bukan Hanya Menggunakan AI Cerita. Anda Menciptakan dengan story321.
Kebanyakan orang tidak kesulitan dengan ide. Mereka kesulitan mengubah ide menjadi sesuatu yang nyata. Story321 mengubah itu. Dengan AI cerita yang tertanam di intinya, story321 membantu Anda:
Mengubah pikiran menjadi cerita terstruktur
Membentuk dan menyempurnakan narasi Anda
Membangun sesuatu yang berkembang seiring waktu
Dari Ide Menjadi Alam Semesta dengan story321
Inilah wujud kreasi ketika AI cerita bekerja dengan cara yang benar.
Sebuah Ide Menjadi Cerita
Mulai dengan percikan, konsep, atau premis kasar. story321 membantu Anda mengubahnya menjadi cerita terstruktur yang benar-benar bisa Anda bangun.
Sebuah Cerita Menjadi Seri
Setelah versi pertama ada, Anda bisa terus melanjutkan. Lanjutkan alur cerita, tambahkan bab, dan kembangkan satu cerita menjadi sesuatu yang terserialisasi dan berkelanjutan.
Sebuah Seri Menjadi Dunia
Seiring cerita saling terhubung, karakter semakin dalam dan latar semakin luas. Apa yang awalnya adalah narasi menjadi dunia dengan logika, ingatan, dan momentumnya sendiri.
Sebuah Dunia Menjadi Visual dan Interaktif
Story321 memungkinkan Anda mengubah dunia itu menjadi komik, video, dan pengalaman interaktif, sehingga kreasi melampaui teks menjadi sesuatu yang bisa dilihat dan dijelajahi orang.
Story321 menghubungkan setiap langkah. Anda tidak hanya menghasilkan konten. Anda sedang membangun sesuatu yang tumbuh.
Cara Baru Mencipta dengan AI Cerita
Story321 mengubah cara kerja AI cerita — bergerak dari sekadar generasi menjadi kreasi berkelanjutan.
Buat Cerita yang Berkembang
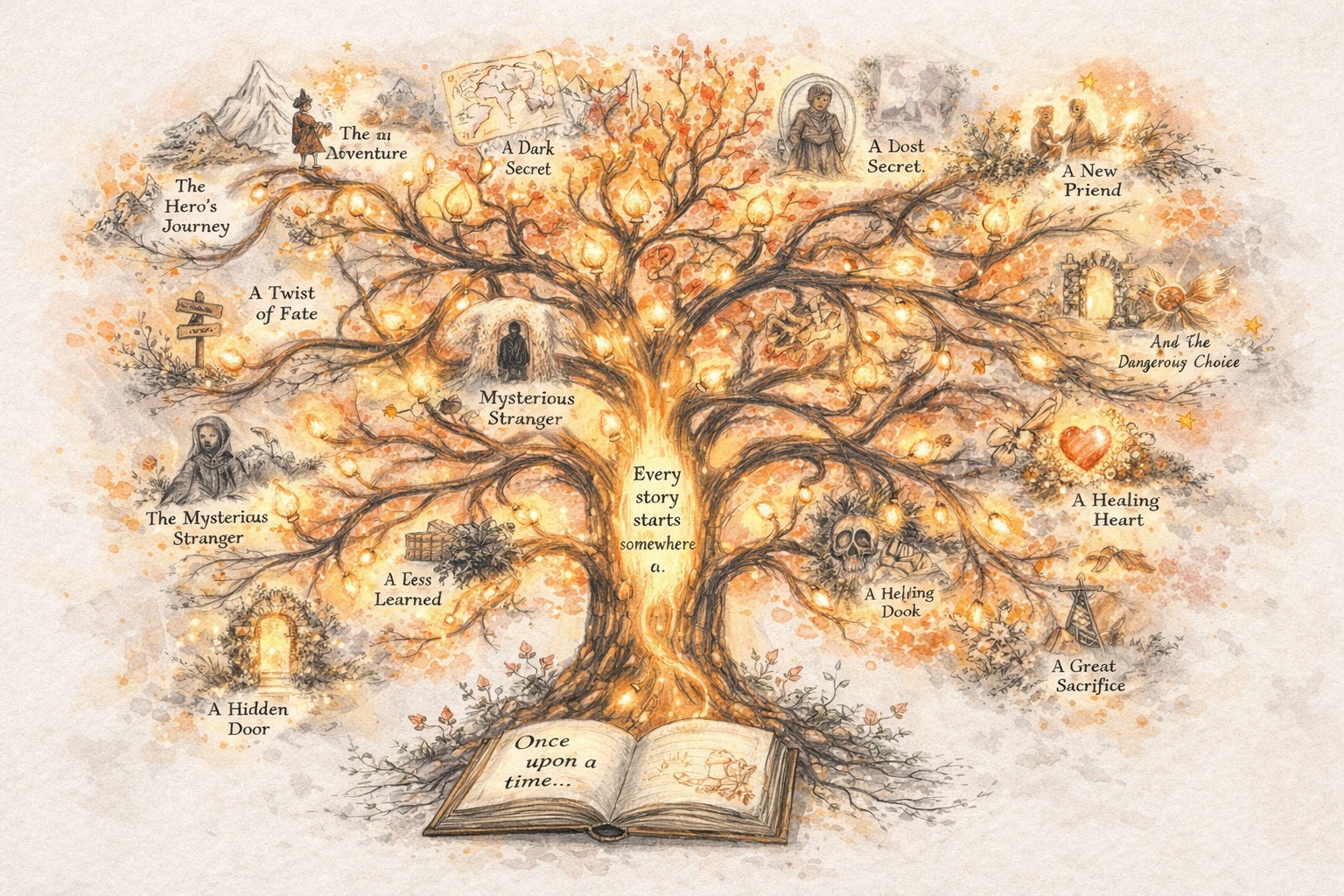
Bangun Karakter yang Tetap Konsisten
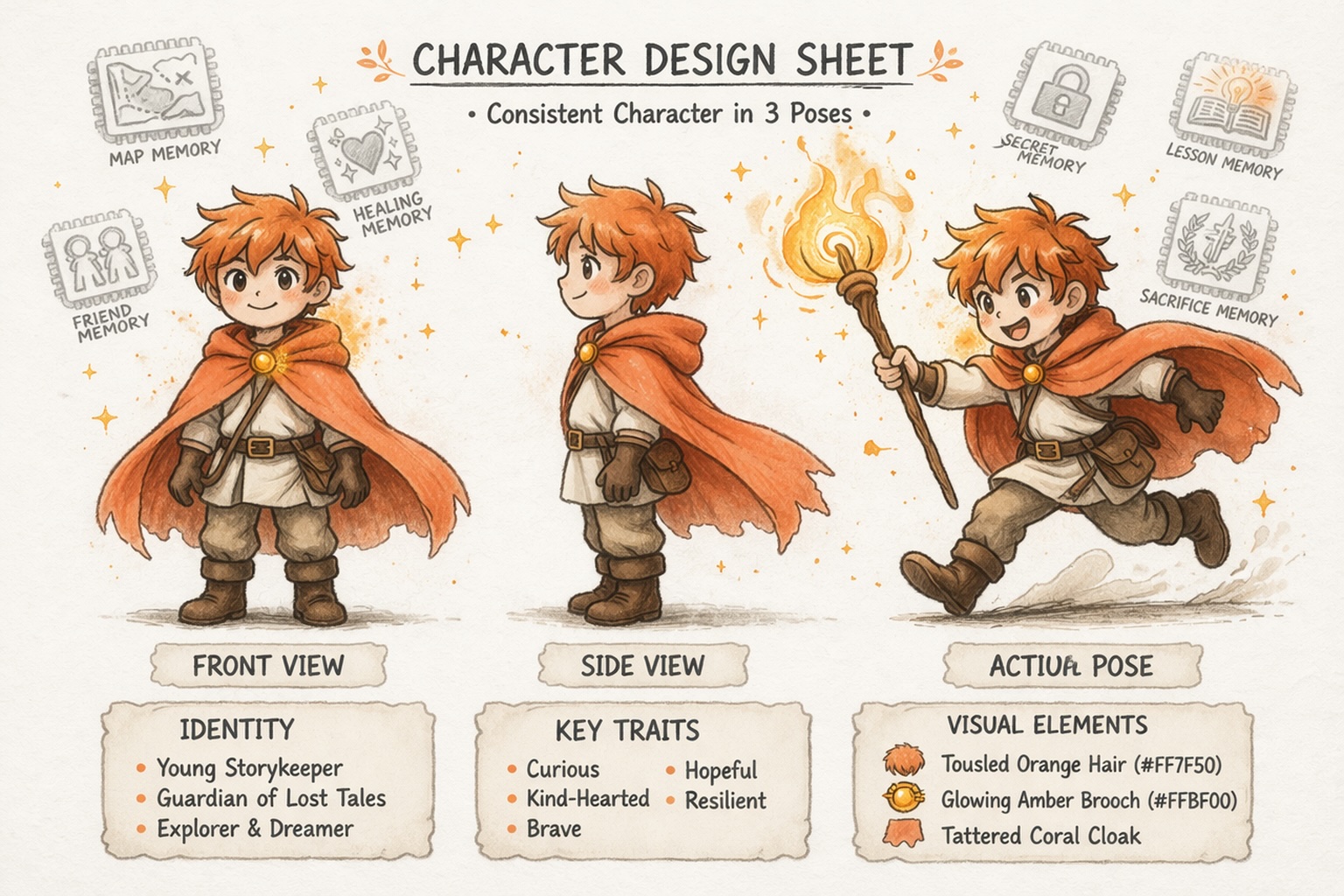
Kembangkan Dunia, Bukan Hanya Prompt
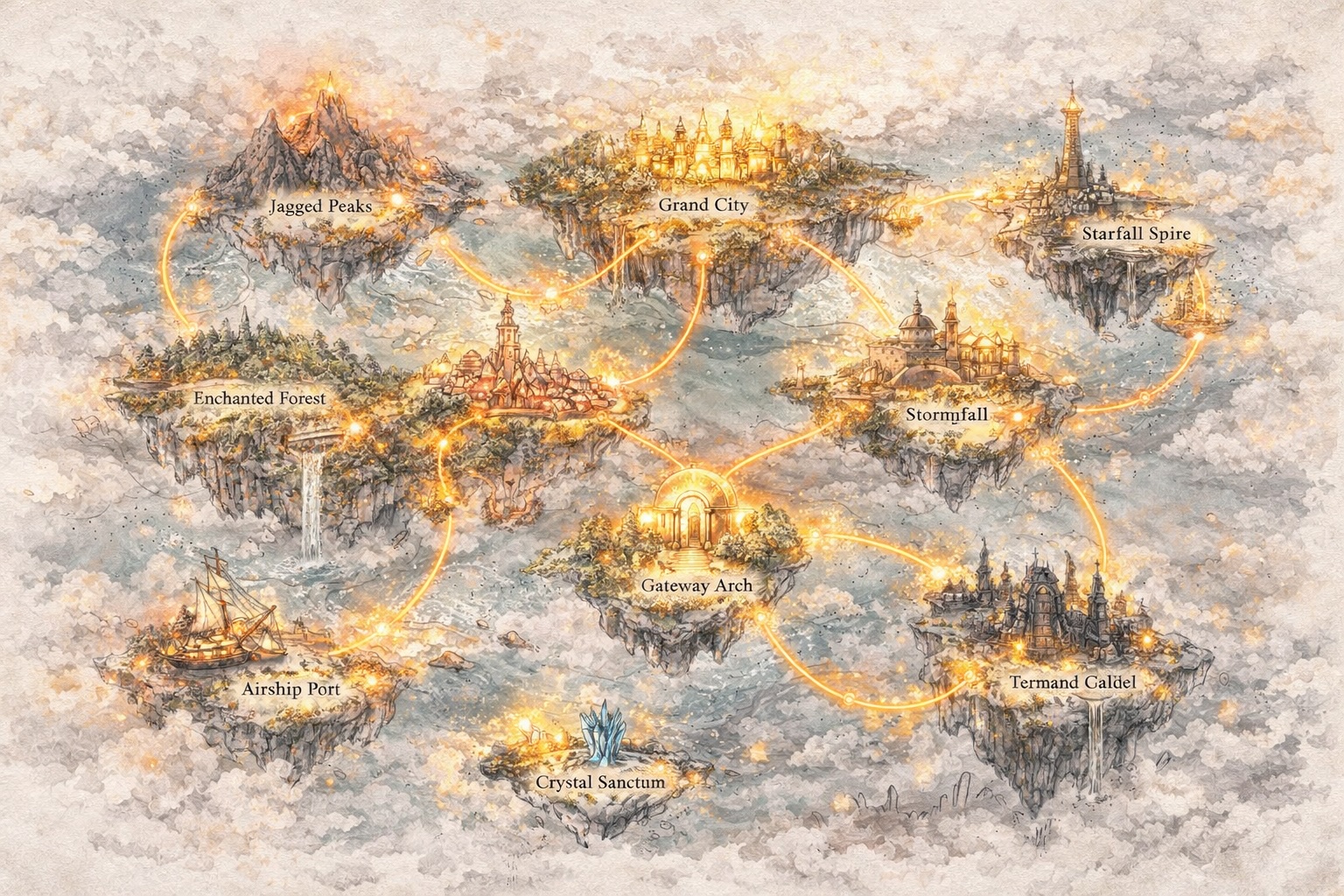
Melampaui Teks

AI Cerita Seharusnya Tidak Berhenti Setelah Satu Keluaran
Alat AI cerita tradisional menghasilkan sekali dan berhenti di situ. Story321 dibangun berbeda. Ia mengubah AI cerita menjadi proses kreatif berkelanjutan di mana setiap langkah membangun dari yang sebelumnya.
Mulai dengan Cerita
Mulai dari satu ide dan bentuk menjadi cerita dengan arah, struktur, dan substansi yang cukup untuk terus dikembangkan.
Lanjutkan Tanpa Mengulang
Alih-alih memulai dari awal setiap kali, teruslah membangun dari apa yang sudah ada. Lanjutkan cerita Anda sambil menjaga konteks dan momentum.
Perluas yang Berhasil
Ambil cerita yang menjanjikan dan kembangkan ke luar. Tambahkan alur, lapisan, karakter, dan detail dunia tanpa kehilangan inti yang membuatnya berhasil.
Transformasi ke Format Baru
Beralih dari cerita ke komik, video, atau pengalaman interaktif. Dengan story321, kreasi terus berkembang alih-alih berakhir pada satu keluaran teks.
Dibuat untuk Berbagai Jenis Kreator
Tidak peduli titik awal Anda, story321 membantu Anda berkembang.
Kreator Baru
Mulai tanpa tekanan. story321 membuat AI cerita mudah diakses, sehingga Anda bisa mencipta tanpa khawatir tentang struktur atau pengalaman.
Kreator Konten
Bergerak lebih cepat dan hasilkan konten berbasis cerita dalam skala besar. story321 mengubah AI cerita menjadi mesin kreatif yang andal.
Pembangun Dunia
Rancang karakter, narasi, dan sistem yang berkembang. story321 membantu Anda menggunakan AI cerita untuk proyek kreatif jangka panjang.
Mengapa story321 Mengubah AI Cerita
AI cerita menjadi lebih kuat ketika ia menjadi bagian dari sebuah sistem. Sistem itu adalah story321.
| Features | Kebanyakan alat AI cerita | story321 |
|---|---|---|
Alur Kreatif | Hasilkan sekali | Membangun terus-menerus |
Memori Naratif | Kehilangan konteks | Menjaga konsistensi naratif |
Ekspansi Format | Berhenti di situ | Berekspansi ke berbagai format |
Pertanyaan yang Sering Diajukan tentang AI cerita
Apa itu AI cerita, dan bagaimana Story321 menggunakannya?
AI cerita adalah penggunaan AI untuk membantu Anda menciptakan cerita, karakter, dan dunia dari ide awal. Story321 menggunakan AI cerita sebagai sistem kreatif, sehingga Anda bisa berpindah dari konsep kasar ke cerita terstruktur dan terus membangun alih-alih memulai dari awal setiap kali.
Bagaimana AI cerita membantu saya menulis cerita lebih cepat?
AI cerita membantu Anda melewati halaman kosong dengan mengubah ide-ide longgar menjadi arah cerita, draf adegan, dan fondasi karakter. Dengan Story321, Anda bisa terus menyempurnakan dan memperluas apa yang sudah berhasil, yang membuat proses penulisan lebih cepat tanpa kehilangan kendali kreatif Anda.
Bisakah AI cerita menjaga konsistensi karakter dan dunia?
Ya, tetapi hanya jika platformnya dibangun untuk kontinuitas. Story321 membantu AI cerita tetap konsisten di seluruh karakter, alur cerita, dan detail dunia, sehingga Anda bisa mengembangkan proyek dari waktu ke waktu alih-alih menghasilkan keluaran yang terputus-putus.
Mengapa memilih Story321 alih-alih alat AI cerita generik?
Kebanyakan alat AI cerita menghasilkan satu respons dan berhenti di situ. Story321 dibangun untuk kreasi berkelanjutan, membantu Anda memperluas cerita menjadi komik, video, dan pengalaman interaktif sambil menjaga arah kreatif, karakter, dan logika dunia yang sama.
Mulai Cerita Pertama Anda dengan story321
Anda tidak perlu pengalaman. Anda tidak perlu ide yang sempurna. Anda hanya perlu memulai. AI cerita akan memberi Anda awalan. story321 akan membantu Anda membangun semua yang terjadi setelahnya.