あなたのアイデアを世界観に変えるストーリーAI
ストーリーを作成し、キャラクターを構築し、それらを漫画、ビデオ、またはゲームに変える―すべてAIで。
単純なアイデアから始めて、ストーリーや世界観、あるいはそれ以上のものに発展させましょう。Story321では、ストーリーAIは単なる出力以上のもの―創造し、拡張し、構築するための方法となります。
あなたはストーリーAIを使うのではなく、story321で創造しています。
多くの人はアイデアに苦労しているのではありません。アイデアを何か現実のものに変えることに苦労しているのです。Story321はそれを変えます。コアに組み込まれたストーリーAIにより、story321はあなたを助けます:
思考を構造化されたストーリーに変える
あなたの物語を形作り、洗練する
時間とともに成長する何かを構築する
story321によるアイデアから宇宙へ
これが、ストーリーAIが正しく機能するときの創造の姿です。
アイデアが物語になる
ひらめき、コンセプト、あるいは大まかな前提から始めましょう。story321は、それを実際に構築できる構造化された物語へと変える手助けをします。
物語がシリーズになる
最初のバージョンが存在すれば、あなたは続けることができます。物語の筋を続け、章を追加し、一つの物語を連載的で持続可能なものへと成長させます。
シリーズが世界観になる
物語がつながると、キャラクターは深みを増し、設定は広がります。物語として始まったものが、独自の論理、記憶、勢いを持つ世界観になります。
世界観がビジュアルでインタラクティブになる
Story321は、その世界観を漫画、ビデオ、インタラクティブ体験へと変えることを可能にし、創造がテキストを超えて、人々が見て探索できる何かへと進化します。
Story321はあらゆるステップをつなぎます。あなたは単にコンテンツを生成しているのではありません。成長する何かを構築しているのです。
ストーリーAIによる新しい創造の道
Story321は、ストーリーAIの働き方を変革します―単純な生成から継続的な創造へと移行します。
進化するストーリーを作る
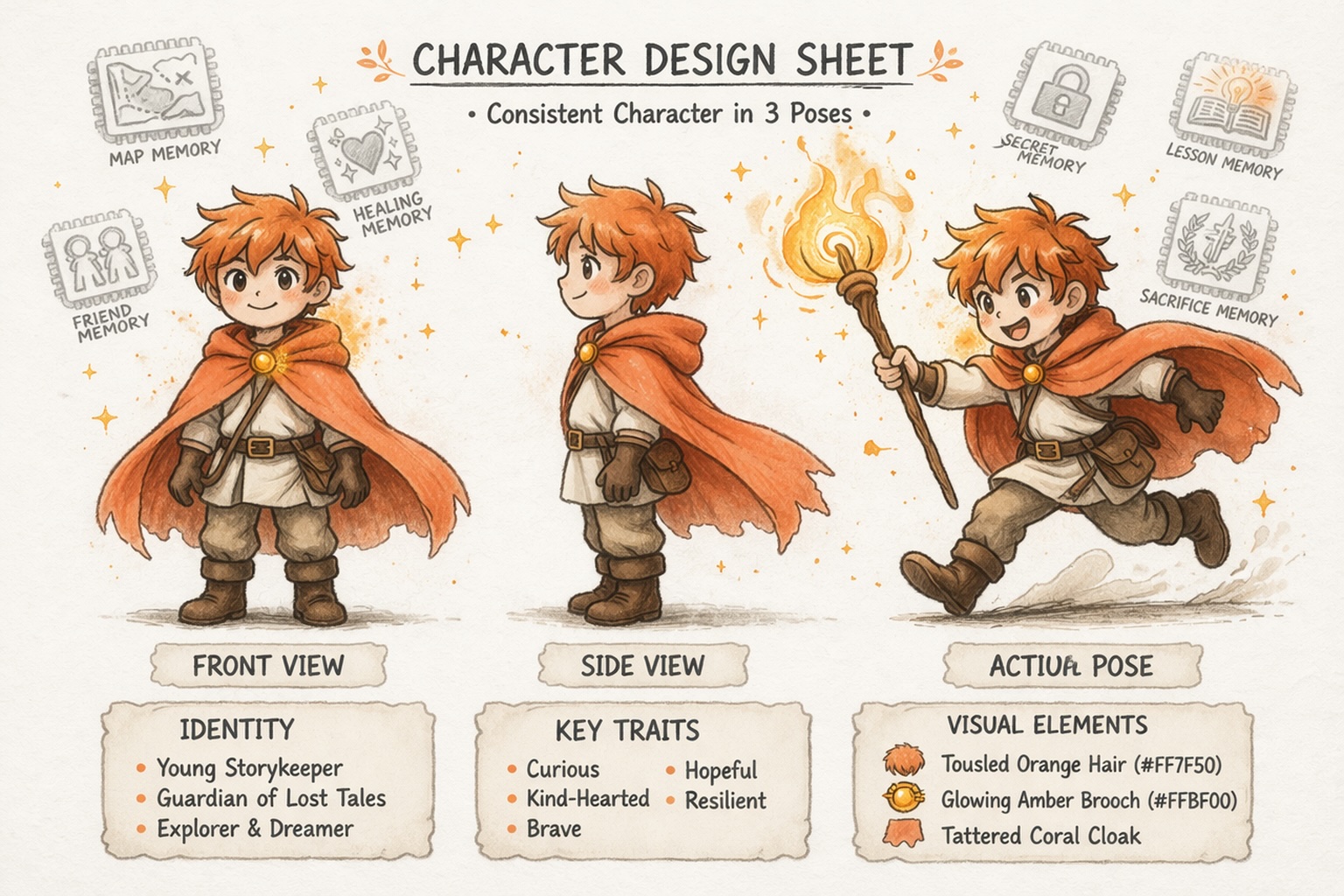
一貫性を保つキャラクターを構築する
プロンプトだけでなく、世界観を開発する
テキストを超える

ストーリーAIは一度の出力で止まるべきではない
従来のストーリーAIツールは一度生成したらそこで止まります。Story321は違う方法で作られています。それは、ストーリーAIを継続的な創造プロセスへと変え、各ステップが前のステップの上に積み上がっていきます。
物語から始める
単一のアイデアから始めて、方向性、構造、発展を続けるのに十分な内容を持つ物語へと形作ります。
リセットせずに続ける
毎回最初からやり直す代わりに、すでに存在するものから構築を続けます。文脈と勢いを保ちながらあなたの物語を続けます。
うまくいったものを拡張する
有望な物語を取り上げ、外側へと成長させます。その物語がうまくいった核心を失うことなく、筋書き、層、キャラクター、世界観の詳細を追加します。
新しいフォーマットへと変容する
物語から漫画、ビデオ、またはインタラクティブ体験へと進みます。Story321では、創造は単一のテキスト出力で終わるのではなく、進化し続けます。
様々な種類のクリエイターのために作られています
あなたの出発点がどこであれ、story321はあなたの成長を助けます。
新米クリエイター
プレッシャーなく始められます。story321はストーリーAIを身近なものにし、構造や経験を心配せずに創造できるようにします。
コンテンツクリエイター
より速く動き、大規模に物語駆動型コンテンツを制作できます。story321はストーリーAIを信頼できる創造エンジンへと変えます。
ワールドビルダー
進化するキャラクター、物語、システムをデザインします。story321は、長期的な創造プロジェクトにストーリーAIを活用する手助けをします。
なぜstory321はストーリーAIを変えるのか
ストーリーAIは、システムの一部となるときにより強力になります。そのシステムがstory321です。
| Features | ほとんどのストーリーAIツール | story321 |
|---|---|---|
創造の流れ | 一度生成 | 継続的に構築 |
物語の記憶 | 文脈を失う | 物語の一貫性を維持 |
フォーマット拡張 | そこで止まる | フォーマットを越えて拡張 |
ストーリーAIに関するよくある質問
ストーリーAIとは何ですか?またStory321はそれをどのように利用しますか?
ストーリーAIとは、AIを活用して、最初のアイデアから物語、キャラクター、世界観を作成する手助けをするものです。Story321はストーリーAIを創造システムとして利用するため、大まかなコンセプトから構造化された物語へと進み、毎回一から始めることなく構築を続けることができます。
ストーリーAIはどのようにして物語をより速く書く手助けをしますか?
ストーリーAIは、まとまりのないアイデアを物語の方向性、場面の下書き、キャラクターの基盤へと変えることで、白紙の状態を乗り越える手助けをします。Story321では、すでにうまくいっているものを洗練し拡張し続けることができるため、創造的なコントロールを失うことなく、執筆プロセスを速めることができます。
ストーリーAIはキャラクターや世界観の一貫性を保つことができますか?
はい、ただし、連続性のために作られたプラットフォームでのみ可能です。Story321は、ストーリーAIがキャラクター、ストーリーライン、世界観の詳細にわたって一貫性を保つ手助けをし、時間の経過とともにプロジェクトを成長させ、無関係な出力を生成することを防ぎます。
汎用的なストーリーAIツールではなく、なぜStory321を選ぶのですか?
ほとんどのストーリーAIツールは一度応答を生成したらそこで止まります。Story321は継続的な創造のために作られており、同じ創造的な方向性、キャラクター、世界観の論理を保ちながら、物語を漫画、ビデオ、インタラクティブ体験へと拡張する手助けをします。
story321であなたの最初の物語を始めましょう
経験は必要ありません。完璧なアイデアも必要ありません。ただ始めるだけです。ストーリーAIが始まりを与えます。story321がその後続くすべてを構築する手助けをします。