Story AI som gjør ideene dine til verdener
Lag historier, bygg karakterer, og gjør dem om til tegneserier, videoer eller spill – alt med AI.
Start med en enkel idé og gjør den til en historie, en verden eller noe enda større. Med story321 blir historie-AI mer enn bare output – det blir en måte å skape, utvide og bygge på.
Du bruker ikke Story AI. Du skaper med story321.
De fleste sliter ikke med ideer. De sliter med å gjøre ideer til noe virkelig. Story321 endrer det. Med historie-AI innebygd i kjernen, hjelper story321 deg med å:
Gjøre tanker om til strukturerte historier
Forme og forbedre din fortelling
Bygge noe som vokser over tid
Fra idé til univers med story321
Slik ser skaping ut når historie-AI fungerer slik den skal.
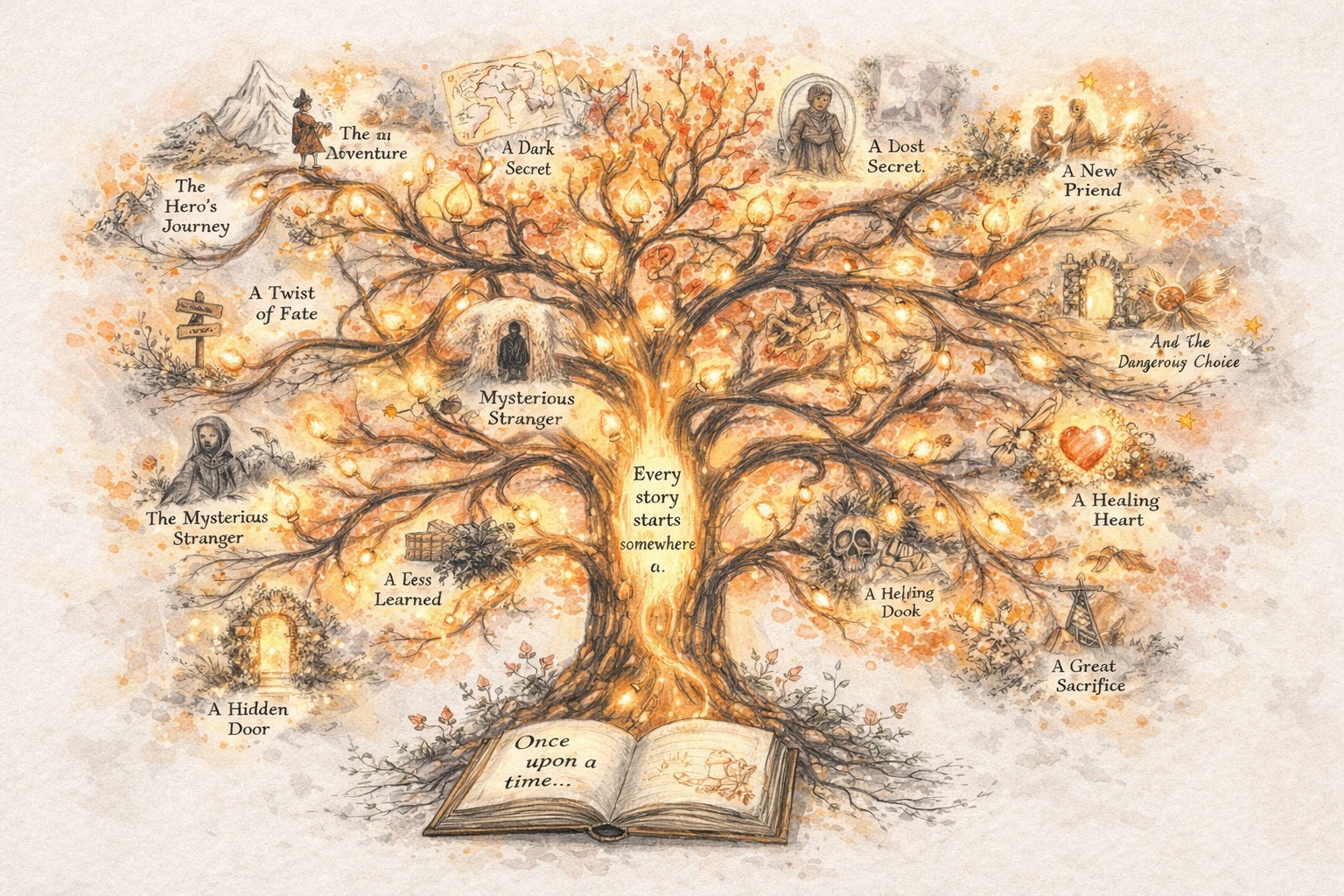
En idé blir til en historie
Start med en gnist, et konsept eller en grov premiss. story321 hjelper deg med å gjøre det om til en strukturt historie du faktisk kan bygge på.
En historie blir til en serie
Når den første versjonen eksisterer, kan du fortsette. Fortsett med ark, legg til kapitler og voks én historie til noe seriemessig og vedvarende.
En serie blir til en verden
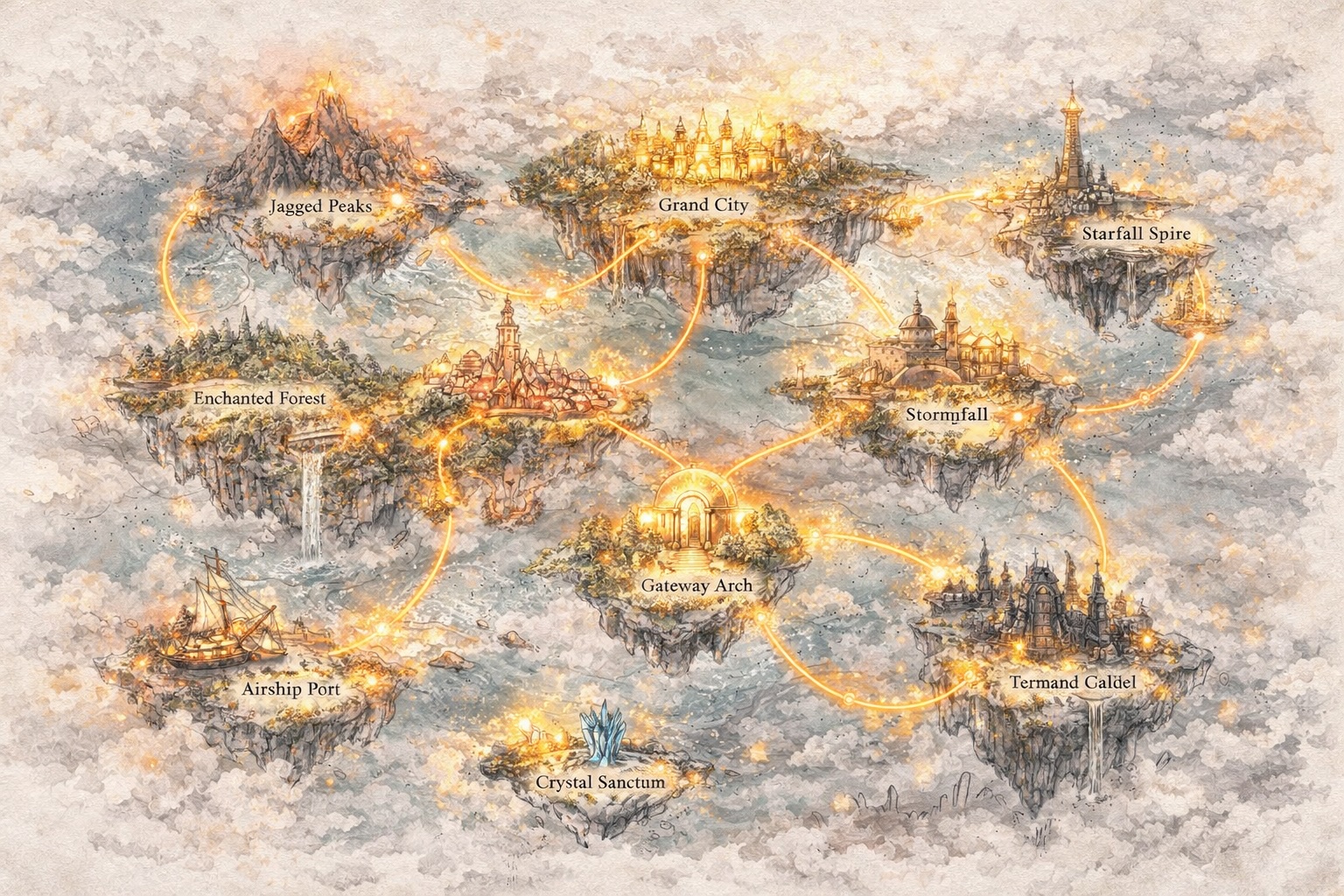
Etter hvert som historier kobles sammen, utdypes karakterer og settinger utvides. Det som begynte som en fortelling blir en verden med sin egen logikk, minne og momentum.
En verden blir visuell og interaktiv
Story321 lar deg forvandle den verdenen til tegneserier, videoer og interaktive opplevelser, slik at skaping går utover tekst og blir til noe folk kan se og utforske.
Story321 kobler sammen hvert steg. Du genererer ikke bare innhold. Du bygger noe som vokser.
En ny måte å skape på med Story AI
Story321 forvandler hvordan historie-AI fungerer – fra enkel generering til kontinuerlig skaping.
Lag historier som utvikler seg
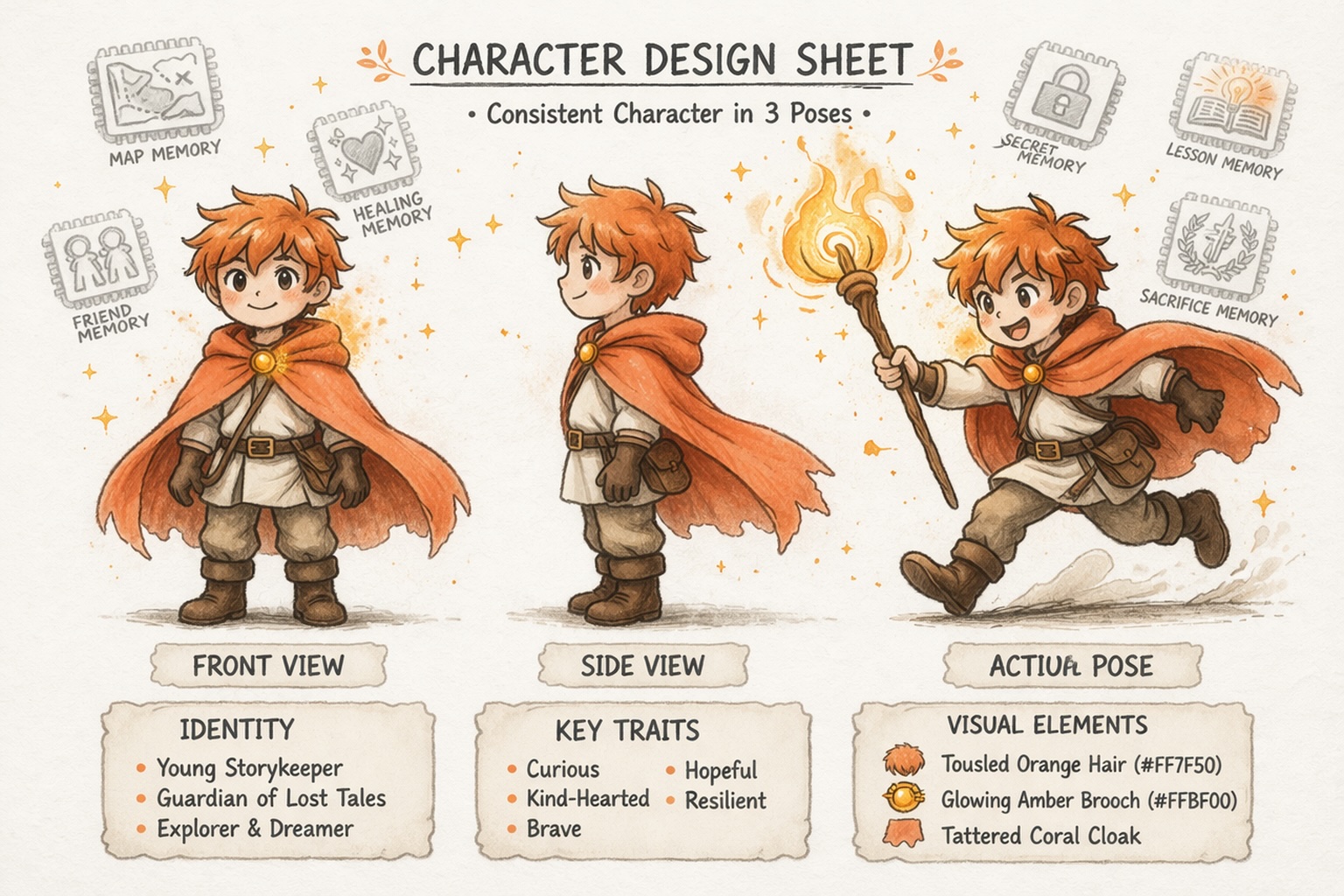
Bygg karakterer som holder seg konsistente
Utvikle verdener, ikke bare prompts
Gå utover tekst

Historie-AI bør ikke stoppe etter én output
Tradisjonelle historie-AI-verktøy genererer én gang og stopper der. Story321 er bygget annerledes. Den gjør historie-AI om til en kontinuerlig kreativ prosess der hvert steg bygger på det forrige.
Start med en historie
Begynn med én enkelt idé og form den til en historie med retning, struktur og nok substans til å fortsette å utvikle.
Fortsett uten å nullstille
I stedet for å starte på nytt hver gang, fortsett å bygge videre på det som allerede finnes. Fortsett historien din mens du bevarer kontekst og momentum.
Utvid det som fungerer
Ta en lovende historie og voks den utover. Legg til ark, lag, karakterer og verdendetaljer uten å miste kjernen i det som fikk det til å fungere.
Forvandle til nye formater
Gå fra historie til tegneserie, video eller interaktiv opplevelse. Med story321 fortsetter skaping å utvikle seg i stedet for å ende med et enkelt tekstoutput.
Bygget for forskjellige typer skapere
Uansett utgangspunkt hjelper story321 deg å vokse.
Nye skapere
Start uten press. story321 gjør historie-AI tilgjengelig, slik at du kan skape uten å bekymre deg for struktur eller erfaring.
Innholdsskapere
Beveg deg raskere og produser historiedrevet innhold i stor skala. story321 gjør historie-AI om til en pålitelig kreativ motor.
Verdensbyggere
Design karakterer, fortellinger og systemer som utvikler seg. story321 hjelper deg med å bruke historie-AI til langsiktige kreative prosjekter.
Hvorfor story321 endrer Story AI
Historie-ai blir mer kraftfull når den er en del av et system. Det systemet er story321.
| Features | De fleste historie-ai-verktøy | story321 |
|---|---|---|
Kreativ flyt | Generer én gang | Bygger kontinuerlig |
Fortellerhukommelse | Mister kontekst | Opprettholder fortellerkonsistens |
Formatutvidelse | Stopper der | Utvides på tvers av formater |
Vanlige spørsmål om historie-ai
Hva er historie-ai, og hvordan bruker Story321 det?
Historie-ai er bruken av AI for å hjelpe deg med å skape historier, karakterer og verdener fra en innledende idé. Story321 bruker historie-ai som et kreativt system, slik at du kan gå fra grove konsepter til strukturerte historier og fortsette å bygge i stedet for å starte på nytt hver gang.
Hvordan hjelper historie-ai meg å skrive historier raskere?
Historie-ai hjelper deg forbi den tomme siden ved å gjøre løse ideer om til historieretninger, scenedråft og karaktergrunnlag. Med Story321 kan du fortsette å forbedre og utvide det som allerede fungerer, noe som gjør skriveprosessen raskere uten å miste din kreative kontroll.
Kan historie-ai holde karakterer og verdener konsistente?
Ja, men bare hvis plattformen er bygget for kontinuitet. Story321 hjelper historie-ai med å holde seg konsistent på tvers av karakterer, historielinjer og verdendetaljer, slik at du kan vokse et prosjekt over tid i stedet for å generere frakoblede outputs.
Hvorfor velge Story321 i stedet for et generisk historie-ai-verktøy?
De fleste historie-ai-verktøy genererer ett svar og stopper der. Story321 er bygget for kontinuerlig skaping, og hjelper deg med å utvide en historie til tegneserier, videoer og interaktive opplevelser mens du beholder samme kreative retning, karakterer og verdenslogikk.
Start din første historie med story321
Du trenger ikke erfaring. Du trenger ikke en perfekt idé. Du trenger bare å starte. Historie-ai vil gi deg begynnelsen. story321 vil hjelpe deg med å bygge alt som kommer etterpå.