Story AI, которое превращает ваши идеи в миры
Создавайте истории, придумывайте персонажей и превращайте их в комиксы, видео или игры — и всё это с помощью ИИ.
Начните с простой идеи и превратите её в историю, мир или нечто большее. С Story321 ИИ для историй становится больше, чем просто инструмент генерации — он становится способом создавать, расширять и строить.
Вы не просто используете ИИ для историй. Вы творите с Story321.
Большинству людей сложно не придумать идею, а воплотить её во что-то реальное. Story321 меняет это. С ИИ для историй в своей основе, Story321 помогает вам:
Превращать мысли в структурированные истории
Формировать и оттачивать своё повествование
Создавать нечто, что развивается со временем
От идеи к вселенной с Story321
Вот как выглядит творчество, когда ИИ для историй работает правильно.
Идея становится историей
Начните с искры, концепции или грубого наброска. Story321 поможет превратить это в структурированную историю, на которую можно реально опереться.
История становится серией
Как только появится первая версия, вы можете продолжать. Развивайте сюжетные арки, добавляйте главы и превращайте одну историю в нечто сериализованное и долгосрочное.
Сериал становится миром
По мере связи историй, персонажи углубляются, а сеттинги расширяются. То, что начиналось как повествование, становится миром со своей логикой, памятью и динамикой.
Мир становится визуальным и интерактивным
Story321 позволяет вам преобразовать этот мир в комиксы, видео и интерактивные проекты, чтобы творчество вышло за рамки текста во что-то, что люди могут увидеть и исследовать.
Story321 связывает каждый шаг. Вы не просто генерируете контент. Вы строите нечто, что растёт.
Новый способ творить с помощью Story AI
Story321 меняет принцип работы ИИ для историй — от простой генерации к непрерывному творчеству.
Создавайте истории, которые эволюционируют
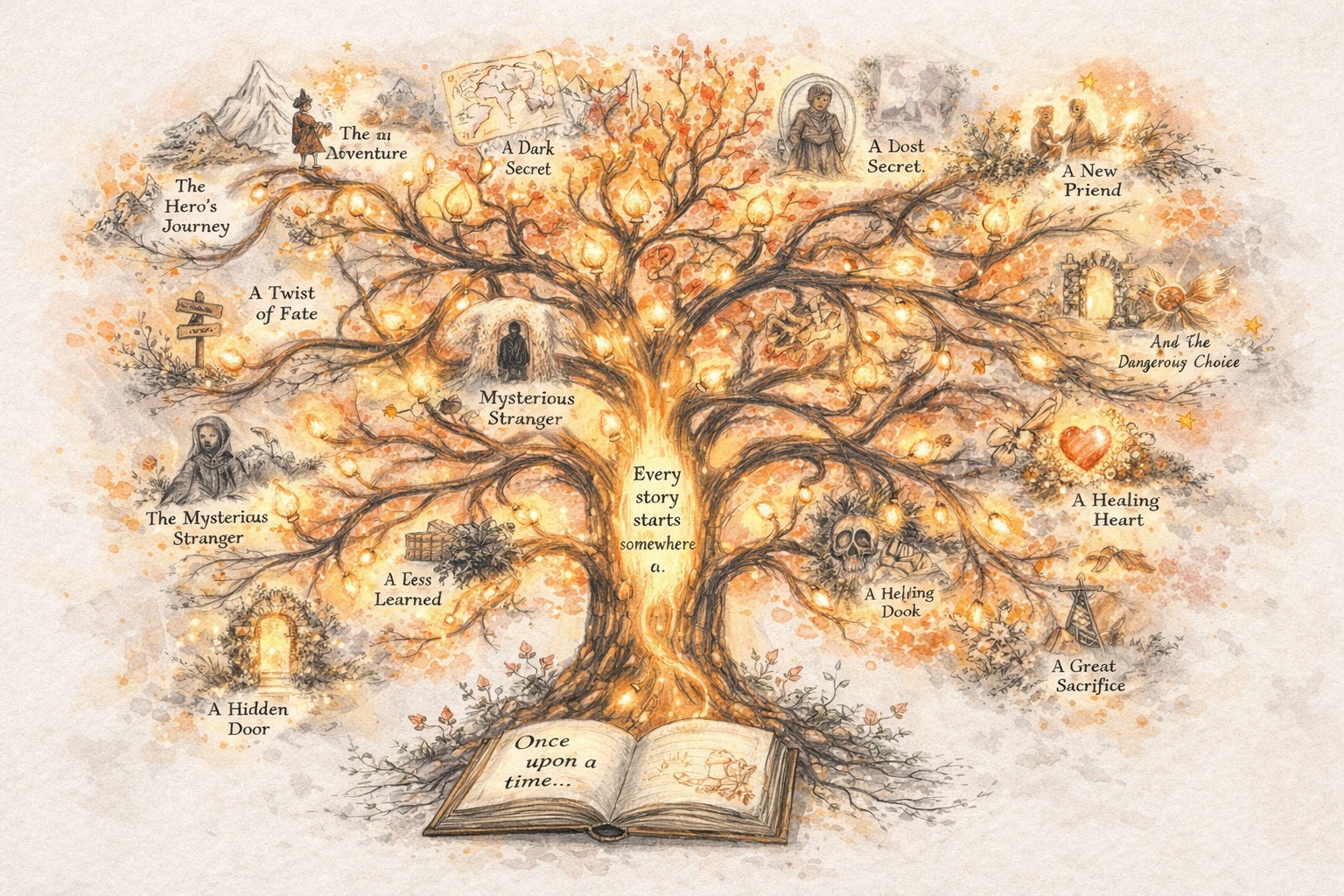
Создавайте персонажей, которые остаются последовательными
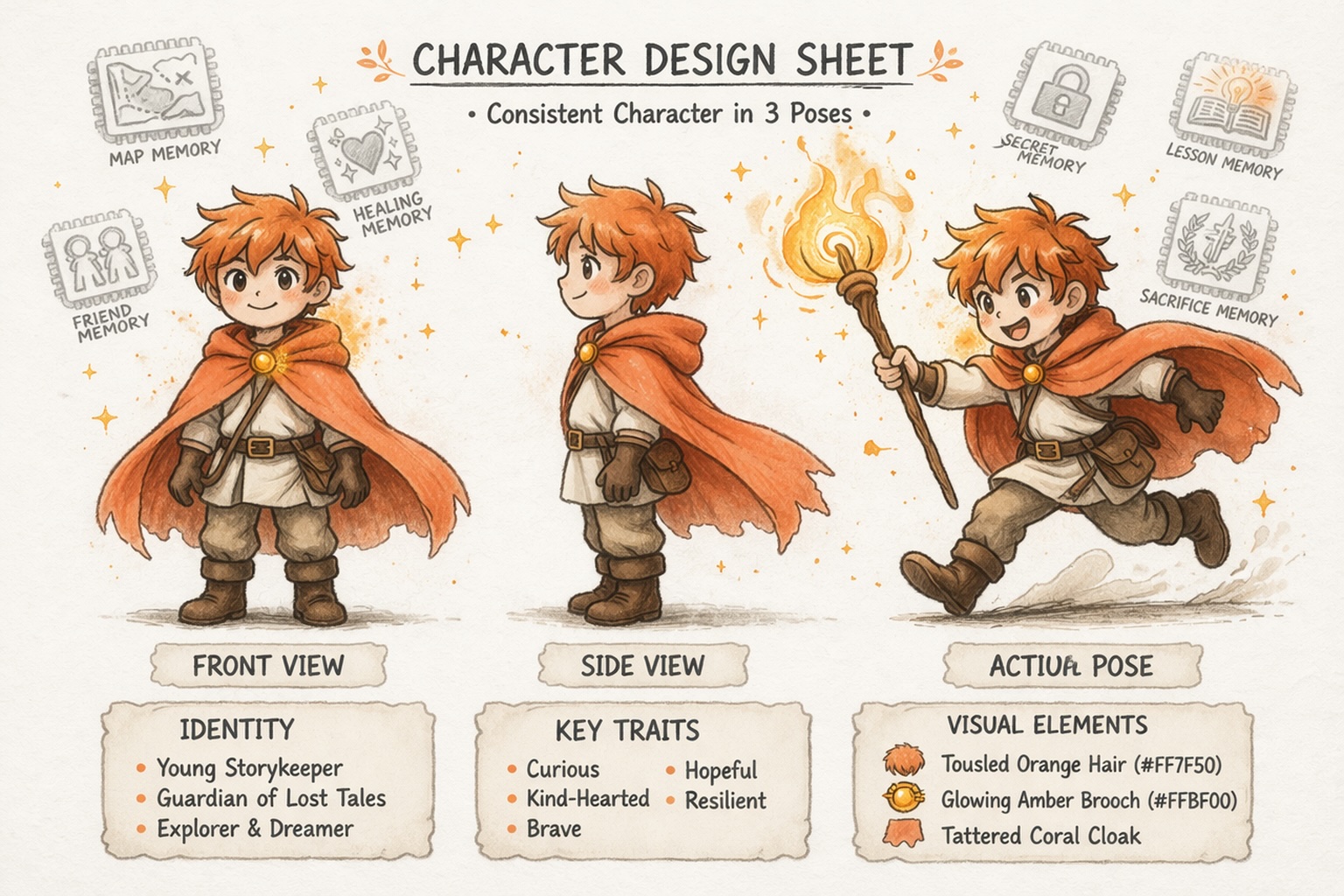
Создавайте миры, а не просто подсказки
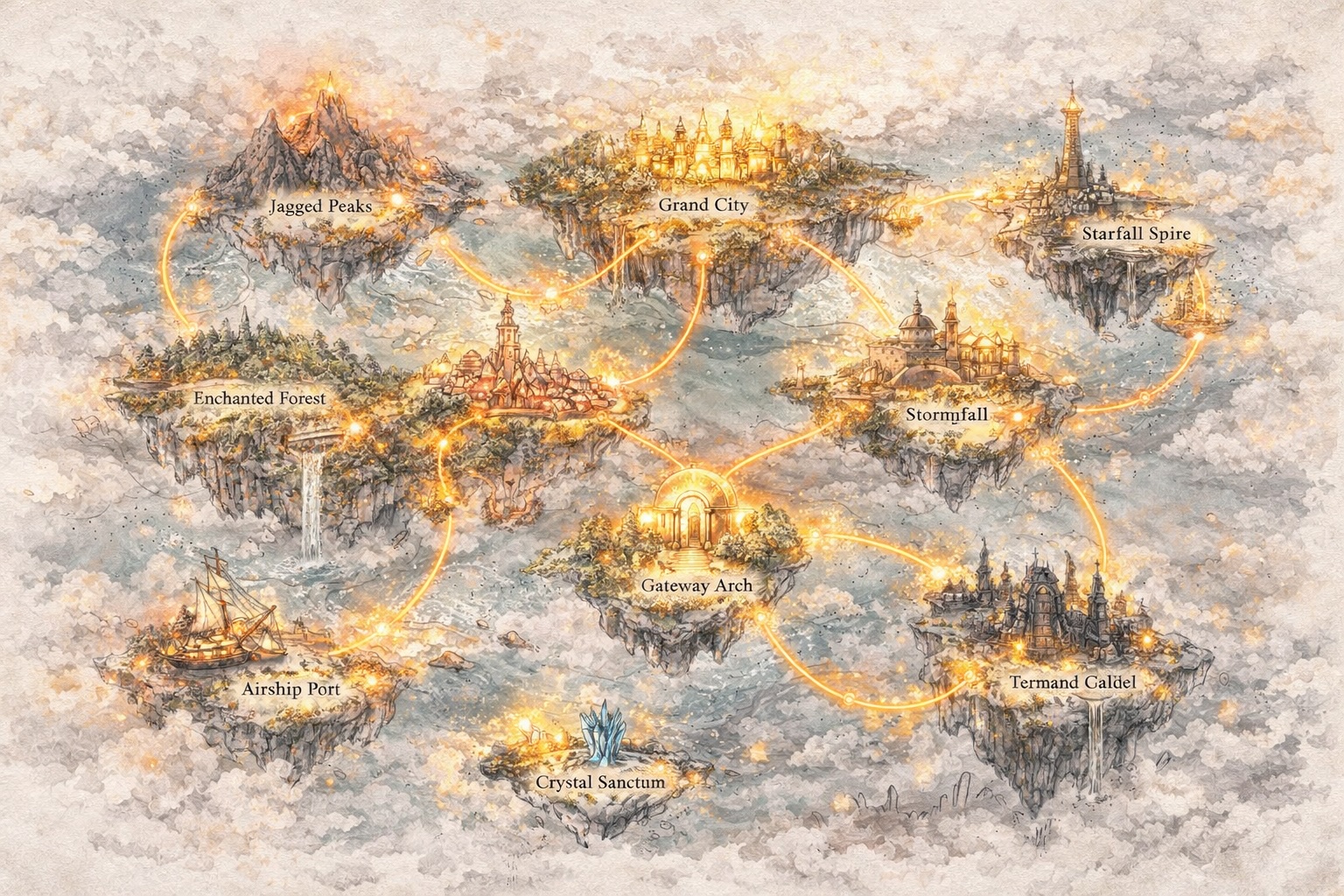
Выходите за рамки текста

Story AI не должен останавливаться на одном результате
Традиционные инструменты ИИ для историй генерируют один раз и останавливаются на этом. Story321 устроен иначе. Он превращает ИИ для историй в непрерывный творческий процесс, где каждый шаг строится на предыдущем.
Начните с истории
Начните с одной идеи и оформите её в историю с направлением, структурой и достаточной основой для дальнейшего развития.
Продолжайте без перезапуска
Вместо того чтобы начинать каждый раз заново, продолжайте строить на том, что уже создано. Развивайте свою историю, сохраняя контекст и динамику.
Расширяйте то, что работает
Возьмите перспективную историю и развивайте её дальше. Добавляйте арки, слои, персонажей и детали мира, не теряя сути того, что сделало её успешной.
Преобразовывайте в новые форматы
Переходите от истории к комиксу, видео или интерактивному проекту. С Story321 творчество продолжает эволюционировать, а не заканчивается на одном текстовом результате.
Создано для разных типов творцов
Независимо от вашей отправной точки, Story321 помогает вам расти.
Начинающие творцы
Начинайте без давления. Story321 делает ИИ для историй доступным, чтобы вы могли творить, не беспокоясь о структуре или опыте.
Создатели контента
Работайте быстрее и создавайте контент на основе историй в масштабе. Story321 превращает ИИ для историй в надёжный творческий двигатель.
Создатели миров
Проектируйте персонажей, сюжеты и системы, которые развиваются. Story321 помогает вам использовать ИИ для историй в долгосрочных творческих проектах.
Почему Story321 меняет Story AI
ИИ для историй становится мощнее, когда он является частью системы. Эта система — Story321.
| Features | Большинство инструментов story ai | Story321 |
|---|---|---|
Творческий поток | Сгенерировать один раз | Строит непрерывно |
Память повествования | Теряет контекст | Сохраняет последовательность повествования |
Расширение форматов | Останавливается на месте | Расширяется на разные форматы |
Часто задаваемые вопросы об ИИ для историй (story ai)
Что такое ИИ для историй и как его использует Story321?
ИИ для историй — это использование искусственного интеллекта для помощи в создании историй, персонажей и миров из начальной идеи. Story321 использует ИИ для историй как творческую систему, позволяя вам перейти от грубых концепций к структурированным историям и продолжать строить, а не начинать каждый раз заново.
Как ИИ для историй помогает мне писать истории быстрее?
ИИ для историй помогает вам преодолеть страх чистого листа, превращая разрозненные идеи в направления для истории, черновики сцен и основы для персонажей. С Story321 вы можете продолжать совершенствовать и расширять то, что уже работает, что делает процесс письма быстрее без потери вашего творческого контроля.
Может ли ИИ для историй поддерживать последовательность персонажей и миров?
Да, но только если платформа создана для преемственности. Story321 помогает ИИ для историй сохранять последовательность в персонажах, сюжетных линиях и деталях мира, чтобы вы могли развивать проект со временем, а не генерировать разрозненные результаты.
Почему стоит выбрать Story321 вместо обычного инструмента ИИ для историй?
Большинство инструментов ИИ для историй генерируют один ответ и останавливаются на этом. Story321 создан для непрерывного творчества, помогая вам расширять историю в комиксы, видео и интерактивные проекты, сохраняя при этом единое творческое направление, персонажей и логику мира.
Начните свою первую историю с Story321
Вам не нужен опыт. Вам не нужна идеальная идея. Вам просто нужно начать. ИИ для историй даст вам начало. Story321 поможет вам построить всё, что будет дальше.