將您的想法化為世界的Story AI
創造故事、建構角色,並將它們轉化為漫畫、影片或遊戲——一切由AI驅動。
從一個簡單的念頭開始,將它變成一個故事、一個世界,或更宏大的事物。在Story321,故事AI不僅是輸出——它成為一種創造、擴展和建構的方式。
您不是在『使用』故事AI。您是在『用Story321創作』。
大多數人不是缺乏想法,而是苦於將想法變成現實。Story321改變了這一點。其核心內建故事AI,協助您:
將思緒轉化為有結構的故事
塑造並潤飾您的敘事
建構能夠隨時間成長的作品
從點子到宇宙——Story321的創作旅程
這正是當故事AI以正確方式運作時,創作應有的樣貌。
一個點子成為一個故事
從靈光一現、一個概念或粗略的前提開始。Story321協助您將其轉化為一個有結構、可供後續建構的故事。
一個故事成為一個系列
一旦有了初版,您便能持續下去。延續劇情線、增添章節,將單一故事發展為連載且持續的系列。
一個系列成為一個世界
隨著故事相互連結,角色更深入,場景更廣闊。最初的一個敘事,終將演變成擁有自身邏輯、記憶和動能的世界。
一個世界變得可視且互動
Story321讓您能將那個世界轉化為漫畫、影片和互動體驗,使創作超越文字,成為人們可見可探之物。
Story321連接了每一步。您不僅是在生成內容。您是在建構一個能持續成長的事物。
用故事AI創作的新方式
Story321轉變了故事AI的運作方式——從簡單生成轉向持續創作。
創造不斷演變的故事
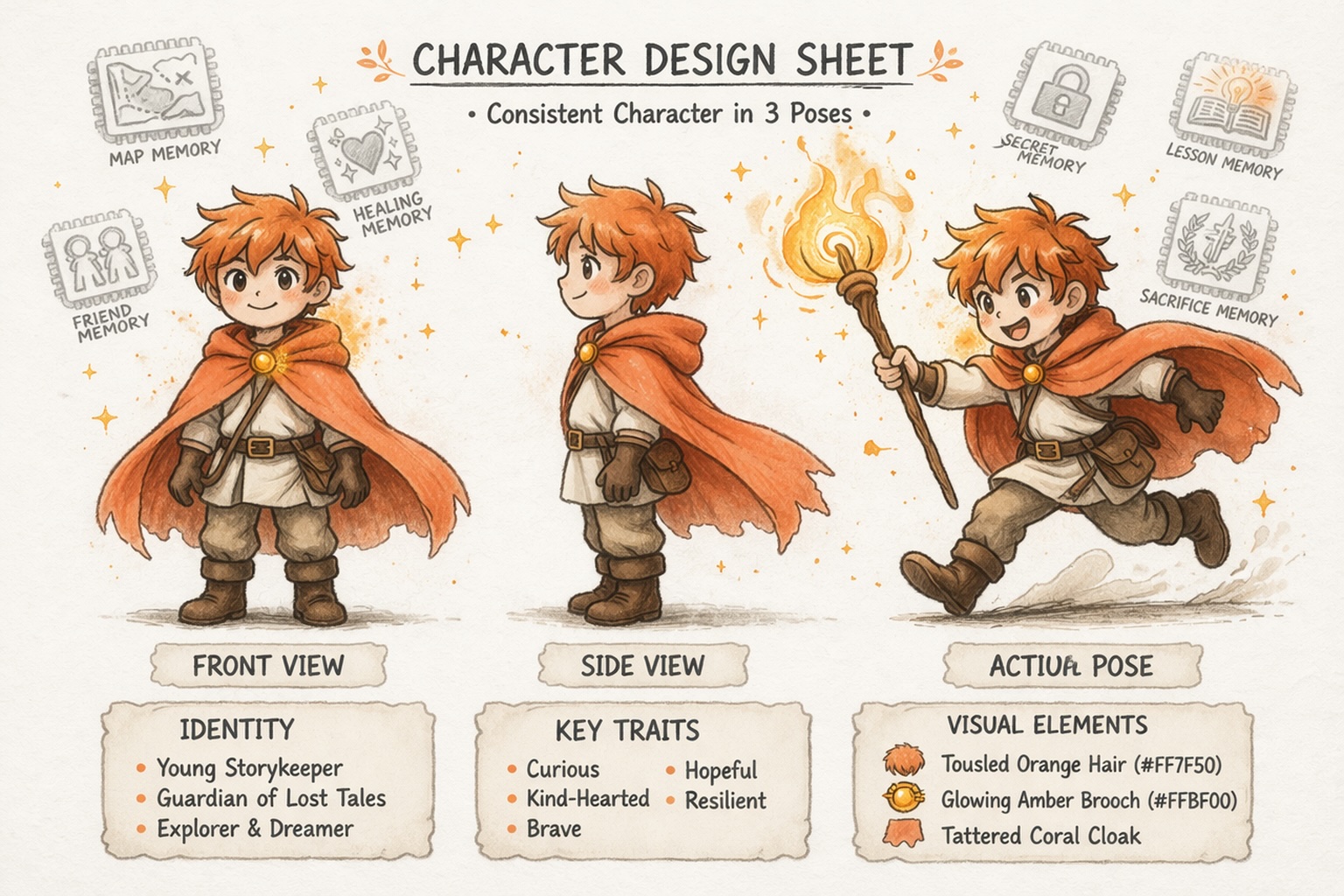
建構始終如一的角色
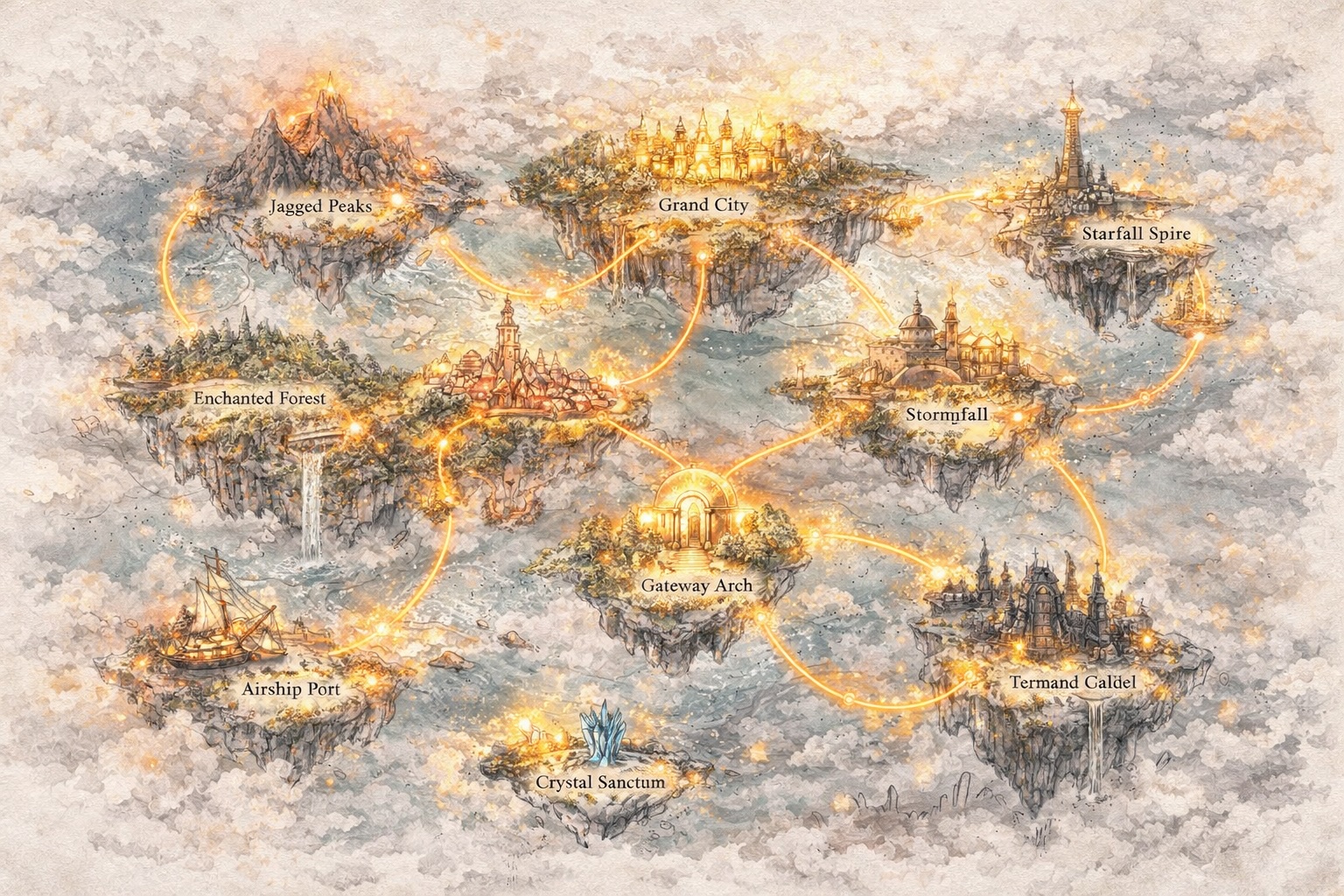
發展世界,而非僅是提示
超越文字的創作

故事AI不該在單次輸出後停止
傳統的故事AI工具生成一次便停下。Story321的設計截然不同。它將故事AI轉變為一個持續的創作過程,每一步都建立在之前的基礎上。
從一個故事開始
從單一想法出發,將其塑造成一個有方向、有結構、且足夠充實以供持續發展的故事。
無需重置,持續創作
無須每次都從頭開始,而是在已有的基礎上繼續建構。延續您的故事,同時保留脈絡與動能。
擴展成功的部分
抓住一個前景看好的故事,向外擴展。增添劇情線、層次、角色和世界細節,而不失其成功核心。
轉化為新形式
從故事轉向漫畫、影片或互動體驗。在Story321,創作持續演化,而非終止於單一文字輸出。
為不同類型的創作者打造
無論您的起點為何,Story321助您成長。
新手創作者
無壓力開始。Story321讓故事AI平易近人,讓您無須擔心結構或經驗即可創作。
內容創作者
更快速產出,大規模製作故事驅動的內容。Story321將故事AI變成可靠的創意引擎。
世界建構者
設計會演進的角色、敘事和體系。Story321幫助您運用故事AI進行長期的創意專案。
為什麼Story321改變了故事AI
當故事AI成為系統的一部分時,它變得更強大。那個系統就是Story321。
| Features | 大多數故事AI工具 | Story321 |
|---|---|---|
創意流程 | 生成一次 | 持續建構 |
敘事記憶 | 失去脈絡 | 維持敘事一致性 |
形式擴展 | 就此停止 | 跨形式擴展 |
關於故事AI的常見問題
什麼是故事AI?Story321如何運用它?
故事AI是利用人工智慧,協助您從初始想法創造故事、角色和世界。Story321將故事AI作為一個創意系統,讓您能從粗略概念轉向有結構的故事,並持續建構,而非每次都從頭開始。
故事AI如何幫助我更快寫作故事?
故事AI協助您克服空白頁面的恐懼,將鬆散的想法轉化為故事方向、場景草稿和角色基礎。藉由Story321,您可以持續潤飾並擴展現有的成果,這讓寫作過程更快,同時不喪失您的創意主導權。
故事AI能保持角色和世界的一致性嗎?
可以,但前提是平台必須為連續性而設計。Story321幫助故事AI在角色、故事情節和世界細節上保持一致,讓您能隨著時間發展專案,而非生成互不相關的輸出。
為什麼選擇Story321而非通用故事AI工具?
大多數故事AI工具生成一次回應就結束。Story321專為持續創作而打造,協助您將故事擴展為漫畫、影片和互動體驗,同時保持相同的創意方向、角色和世界邏輯。