Story AI That Turns Your Ideas into Worlds
Create stories, build characters, and turn them into comics, videos, or games — all with AI.
Start with a simple idea and turn it into a story, a world, or something even bigger. With story321, story ai becomes more than output—it becomes a way to create, expand, and build.
You’re Not Using Story AI. You’re Creating with story321.
Most people don’t struggle with ideas. They struggle with turning ideas into something real. Story321 changes that. With story ai built into its core, story321 helps you:
Turn thoughts into structured stories
Shape and refine your narrative
Build something that grows over time
From Idea to Universe with story321
This is what creation looks like when story ai works the right way.
An Idea Becomes a Story
Start with a spark, a concept, or a rough premise. story321 helps you turn it into a structured story you can actually build on.
A Story Becomes a Series
Once the first version exists, you can keep going. Continue arcs, add chapters, and grow one story into something serialized and sustained.
A Series Becomes a World
As stories connect, characters deepen and settings expand. What began as a narrative becomes a world with its own logic, memory, and momentum.
A World Becomes Visual and Interactive
Story321 lets you transform that world into comics, videos, and interactive experiences, so creation moves beyond text into something people can see and explore.
Story321 connects every step. You’re not just generating content. You’re building something that grows.
A New Way to Create with Story AI
Story321 transforms how story ai works—moving from simple generation to continuous creation.
Create Stories That Evolve
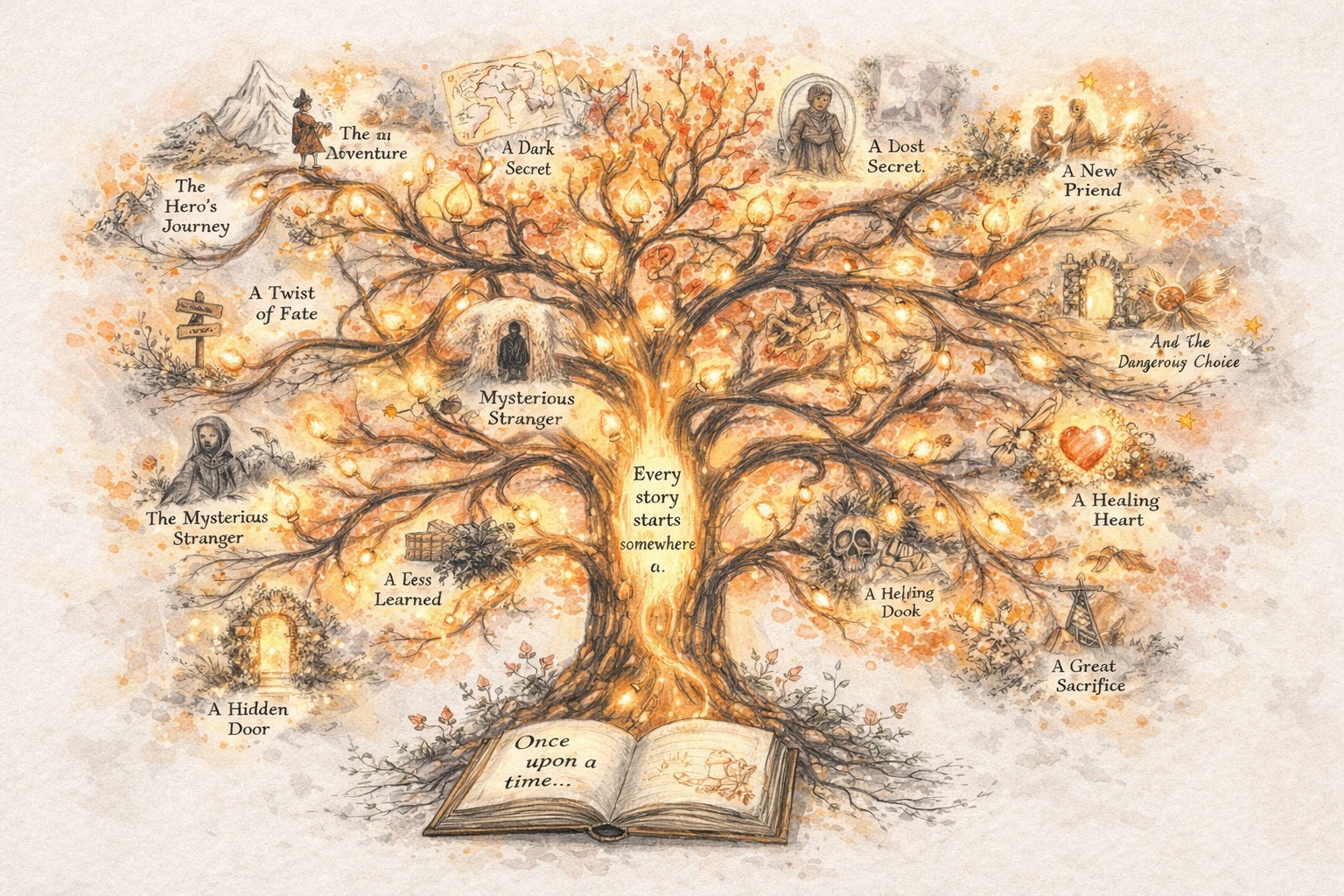
Build Characters That Stay Consistent
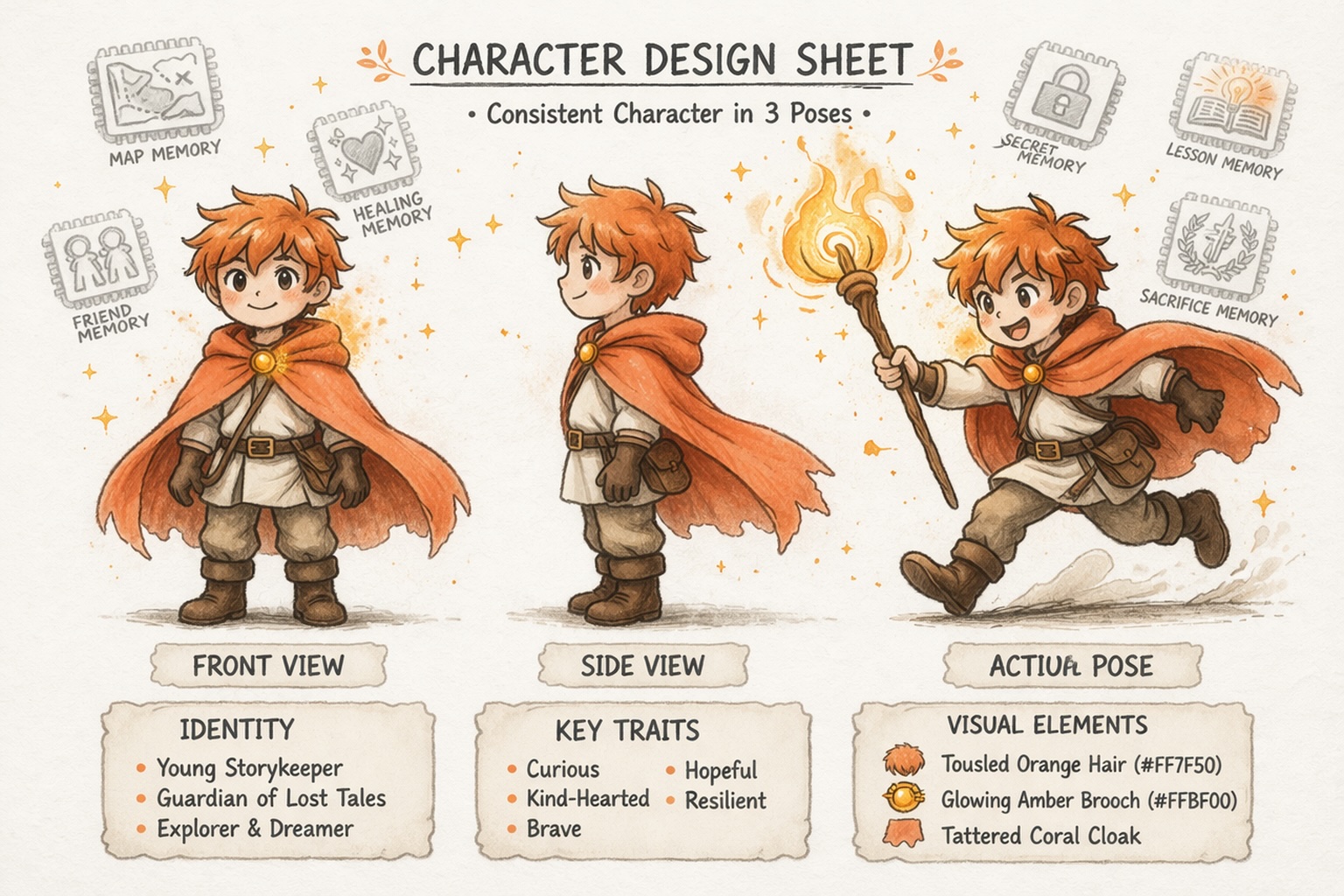
Develop Worlds, Not Just Prompts
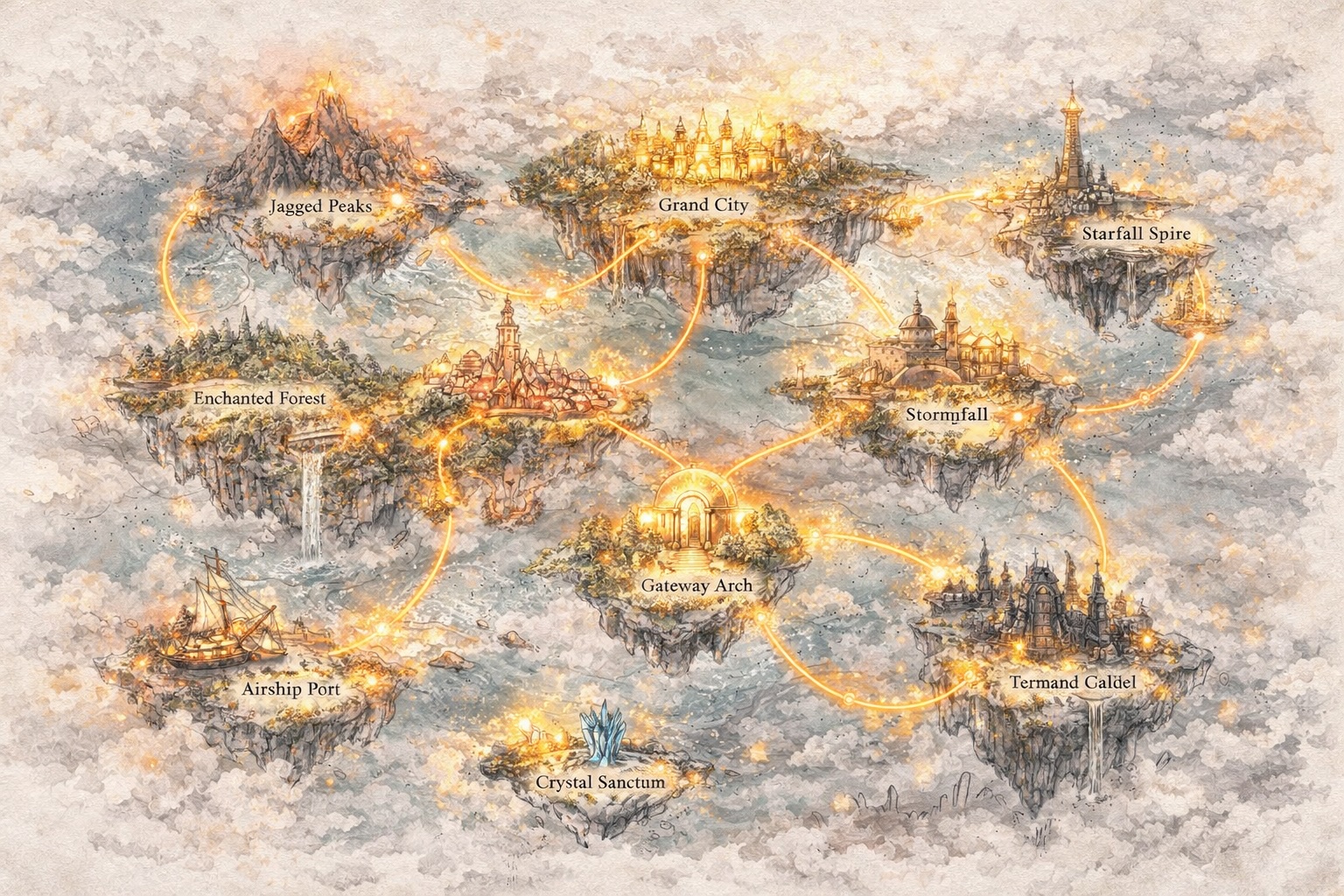
Go Beyond Text

Story AI Shouldn’t Stop After One Output
Traditional story ai tools generate once and stop there. Story321 is built differently. It turns story ai into a creative system, so you can build something that grows.
Start with a Story
Start with a story that has direction, substance, and room to grow, instead of a one-time output.
Continue Without Losing Context
Keep building on what you’ve already created. Story321 helps story ai remember characters, plot points, and world details.
Expand Across Formats
Turn stories into comics, videos, and interactive experiences. With story321, story ai doesn’t stop at text.
Grow Over Time
What starts as a simple story can become a series, a world, or a multimedia project. Story321 turns story ai into a long-term creative partner.
Who Uses Story321?
Story321 is built for creators who want to build, not just generate.
New Writers
Get past the blank page and start building a story with structure and momentum.
Content Creators
Produce story-driven content faster, with consistent characters and narrative flow.
World Builders
Design interconnected stories, characters, and settings that evolve over time.
Dlaczego story321 zmienia Sztuczną Inteligencję do Historii
Sztuczna inteligencja do historii staje się potężniejsza, gdy jest częścią systemu. Tym systemem jest story321.
| Features | Większość narzędzi sztucznej inteligencji do historii | story321 |
|---|---|---|
Kreatywny Przepływ | Wygeneruj raz | Buduje w sposób ciągły |
Pamięć Narracyjna | Tracisz kontekst | Utrzymuje spójność narracji |
Rozszerzenie Formatów | Zatrzymaj się tam | Rozszerza się na różne formaty |
Frequently Asked Questions about story ai
What is story ai, and how does Story321 use it?
story ai is the use of AI to help you create stories, characters, and worlds from an initial idea. Story321 uses story ai as a creative system, so you can move from rough concepts to structured stories and keep building instead of starting over each time.
How does story ai help me write stories faster?
story ai helps you overcome the blank page by turning loose ideas into story directions, scene drafts, and character foundations. With Story321, you can keep refining and extending what already works, which speeds up writing without sacrificing creative control.
Can story ai keep characters and worlds consistent?
Yes, but only if the platform is designed for continuity. Story321 helps story ai maintain consistency across characters, storylines, and world details, so you can develop a project over time instead of producing disconnected outputs.
Why choose Story321 over a generic story ai tool?
Most story ai tools generate a single response and stop there. Story321 is built for continuous creation, helping you expand a story into comics, videos, and interactive experiences while keeping the same creative direction, characters, and world logic.
Start Your First Story with story321
You don’t need experience. You don’t need a perfect idea. You just need to start. story ai will give you the beginning. story321 will help you build everything that comes after.